Adversarial Subword Regularization for Robust Neural Machine Translation
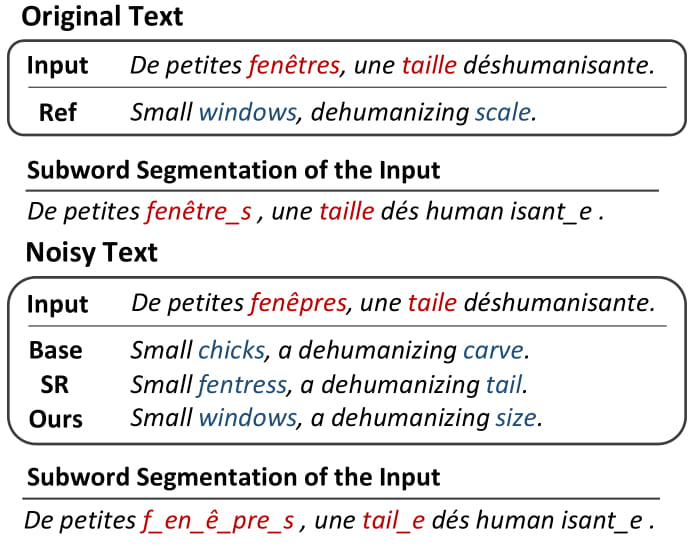
Exposing diverse subword segmentations to neural machine translation (NMT) models often improves the robustness of machine translation as NMT models can experience various subword candidates. However, the diversification of subword segmentations mostly relies on the pre-trained subword language models from which erroneous segmentations of unseen words are less likely to be sampled. In this paper, we present adversarial subword regularization (ADVSR) to study whether gradient signals during training can be a substitute criterion for exposing diverse subword segmentations. We experimentally show that our model-based adversarial samples effectively encourage NMT models to be less sensitive to segmentation errors and improve the performance of NMT models in low-resource and out-domain datasets.
PDF Abstract Findings of 2020 PDF Findings of 2020 Abstract


 MTNT
MTNT
