Bridging Textual and Tabular Data for Cross-Domain Text-to-SQL Semantic Parsing
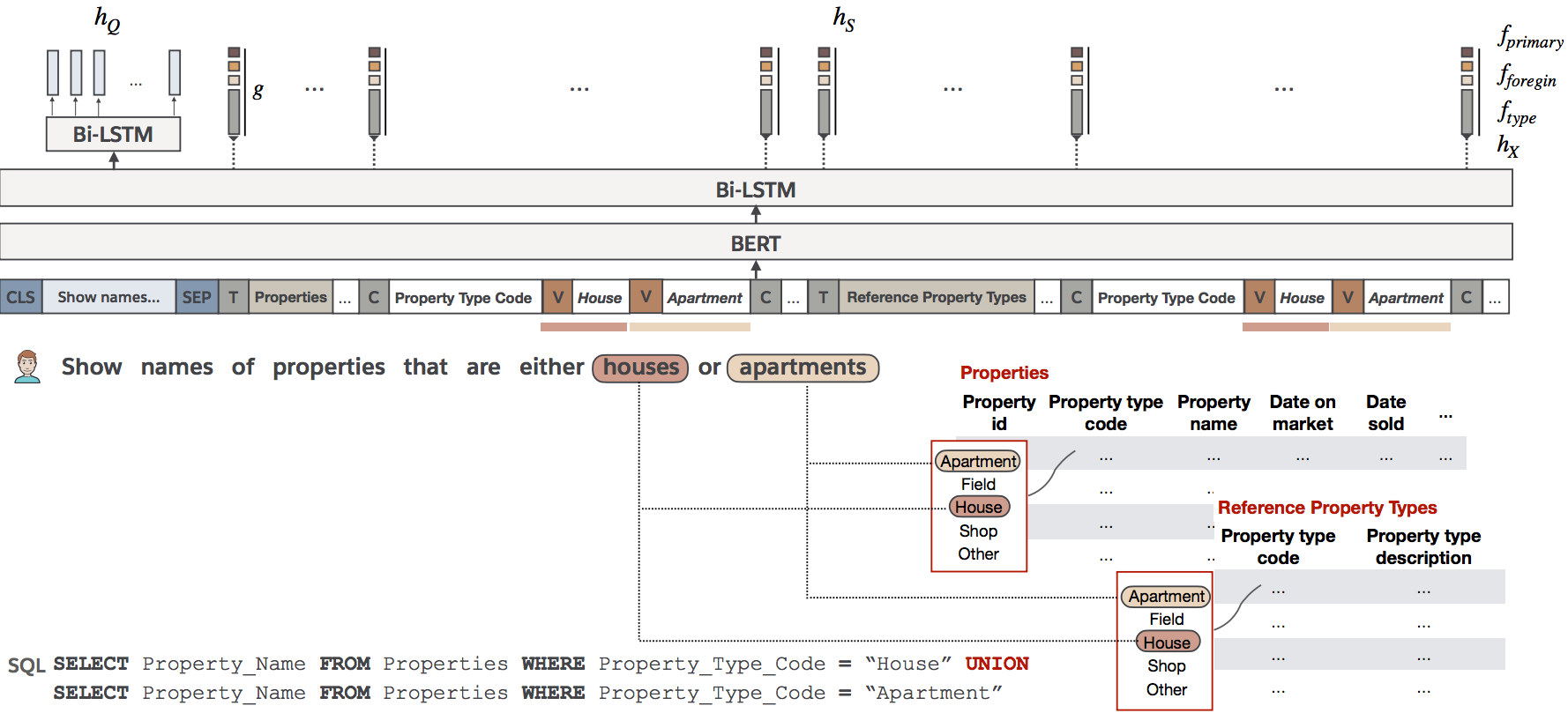
We present BRIDGE, a powerful sequential architecture for modeling dependencies between natural language questions and relational databases in cross-DB semantic parsing. BRIDGE represents the question and DB schema in a tagged sequence where a subset of the fields are augmented with cell values mentioned in the question. The hybrid sequence is encoded by BERT with minimal subsequent layers and the text-DB contextualization is realized via the fine-tuned deep attention in BERT. Combined with a pointer-generator decoder with schema-consistency driven search space pruning, BRIDGE attained state-of-the-art performance on popular cross-DB text-to-SQL benchmarks, Spider (71.1\% dev, 67.5\% test with ensemble model) and WikiSQL (92.6\% dev, 91.9\% test). Our analysis shows that BRIDGE effectively captures the desired cross-modal dependencies and has the potential to generalize to more text-DB related tasks. Our implementation is available at \url{https://github.com/salesforce/TabularSemanticParsing}.
PDF Abstract Findings of 2020 PDF Findings of 2020 Abstract


 WikiSQL
WikiSQL
