Learning to Perturb Word Embeddings for Out-of-distribution QA
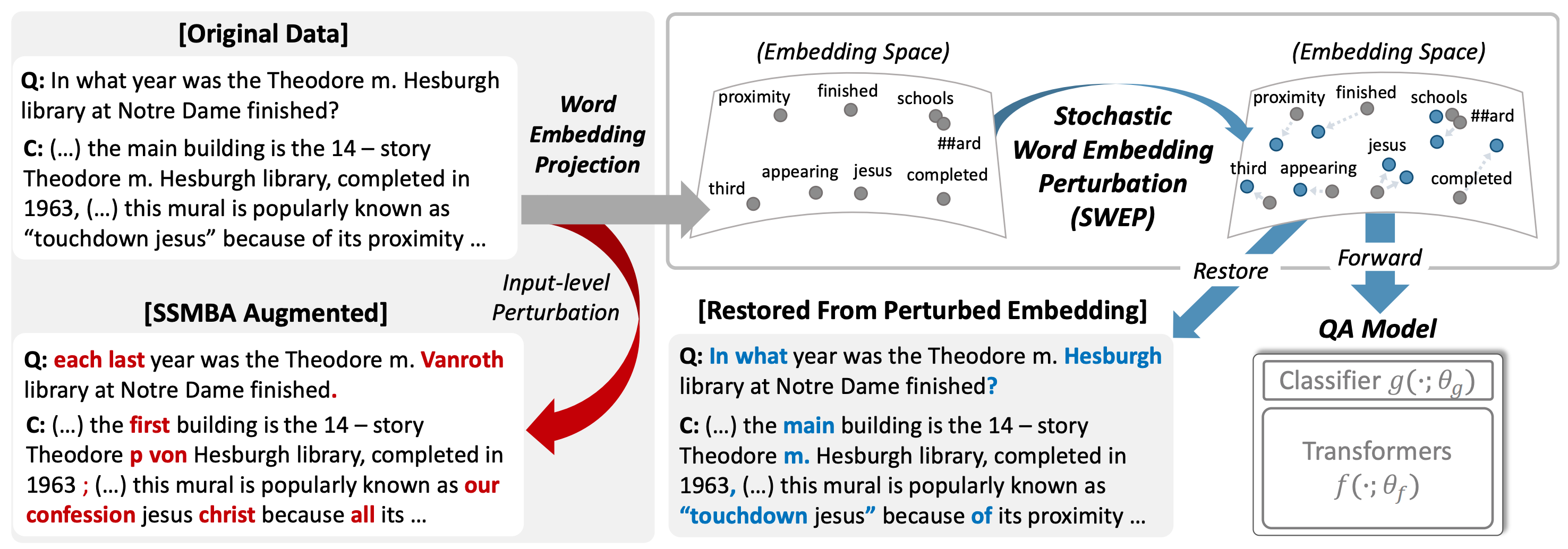
QA models based on pretrained language mod-els have achieved remarkable performance on various benchmark datasets.However, QA models do not generalize well to unseen data that falls outside the training distribution, due to distributional shifts.Data augmentation (DA) techniques which drop/replace words have shown to be effective in regularizing the model from overfitting to the training data.Yet, they may adversely affect the QA tasks since they incur semantic changes that may lead to wrong answers for the QA task. To tackle this problem, we propose a simple yet effective DA method based on a stochastic noise generator, which learns to perturb the word embedding of the input questions and context without changing their semantics. We validate the performance of the QA models trained with our word embedding perturbation on a single source dataset, on five different target domains.The results show that our method significantly outperforms the baselineDA methods. Notably, the model trained with ours outperforms the model trained with more than 240K artificially generated QA pairs.
PDF Abstract ACL 2021 PDF ACL 2021 Abstract



 SQuAD
SQuAD
 BioASQ
BioASQ
