Attend What You Need: Motion-Appearance Synergistic Networks for Video Question Answering
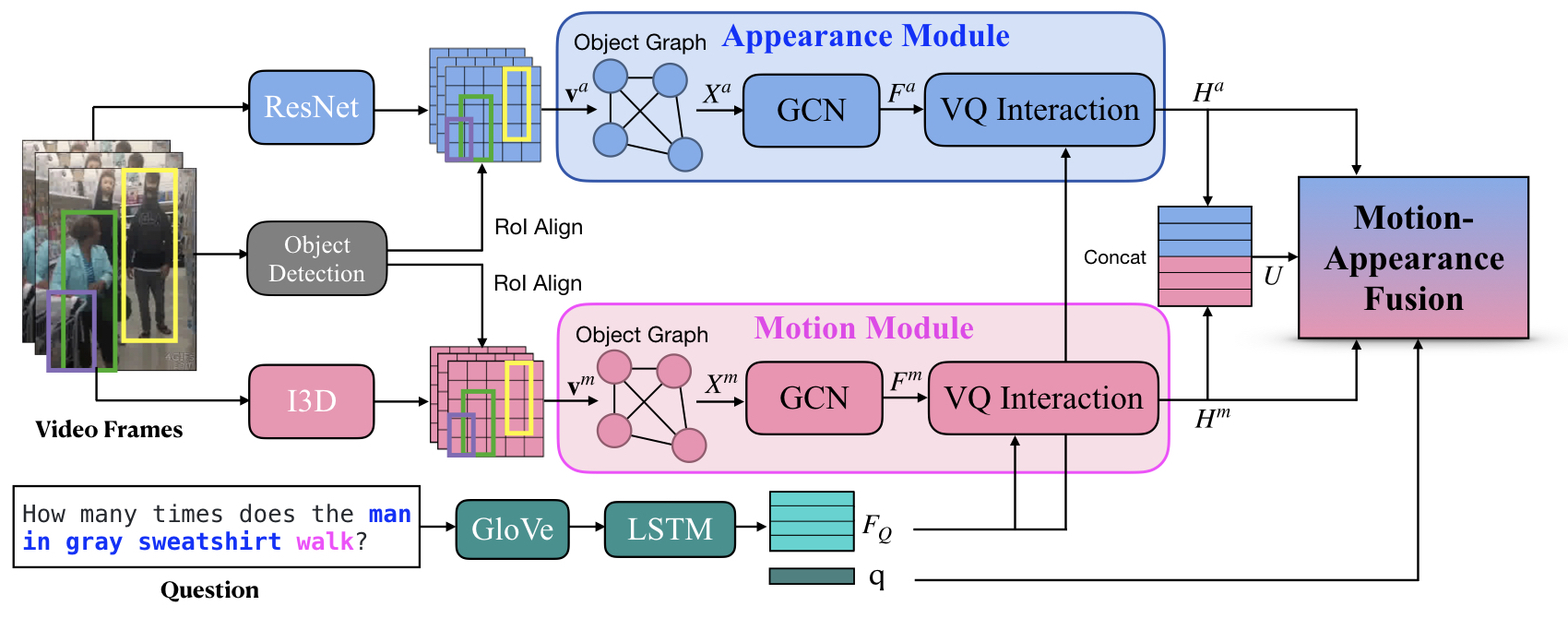
Video Question Answering is a task which requires an AI agent to answer questions grounded in video. This task entails three key challenges: (1) understand the intention of various questions, (2) capturing various elements of the input video (e.g., object, action, causality), and (3) cross-modal grounding between language and vision information. We propose Motion-Appearance Synergistic Networks (MASN), which embed two cross-modal features grounded on motion and appearance information and selectively utilize them depending on the question's intentions. MASN consists of a motion module, an appearance module, and a motion-appearance fusion module. The motion module computes the action-oriented cross-modal joint representations, while the appearance module focuses on the appearance aspect of the input video. Finally, the motion-appearance fusion module takes each output of the motion module and the appearance module as input, and performs question-guided fusion. As a result, MASN achieves new state-of-the-art performance on the TGIF-QA and MSVD-QA datasets. We also conduct qualitative analysis by visualizing the inference results of MASN. The code is available at https://github.com/ahjeongseo/MASN-pytorch.
PDF Abstract ACL 2021 PDF ACL 2021 Abstract


 Visual Question Answering
Visual Question Answering
