Team Enigma at ArgMining-EMNLP 2021: Leveraging Pre-trained Language Models for Key Point Matching
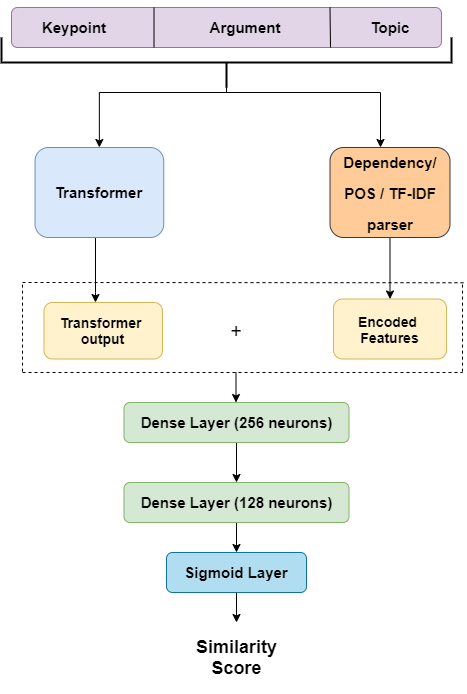
We present the system description for our submission towards the Key Point Analysis Shared Task at ArgMining 2021. Track 1 of the shared task requires participants to develop methods to predict the match score between each pair of arguments and keypoints, provided they belong to the same topic under the same stance. We leveraged existing state of the art pre-trained language models along with incorporating additional data and features extracted from the inputs (topics, key points, and arguments) to improve performance. We were able to achieve mAP strict and mAP relaxed score of 0.872 and 0.966 respectively in the evaluation phase, securing 5th place on the leaderboard. In the post evaluation phase, we achieved a mAP strict and mAP relaxed score of 0.921 and 0.982 respectively. All the codes to generate reproducible results on our models are available on Github.
PDF Abstract EMNLP (ArgMining) 2021 PDF EMNLP (ArgMining) 2021 Abstract

