Enhancing Interpretable Clauses Semantically using Pretrained Word Representation
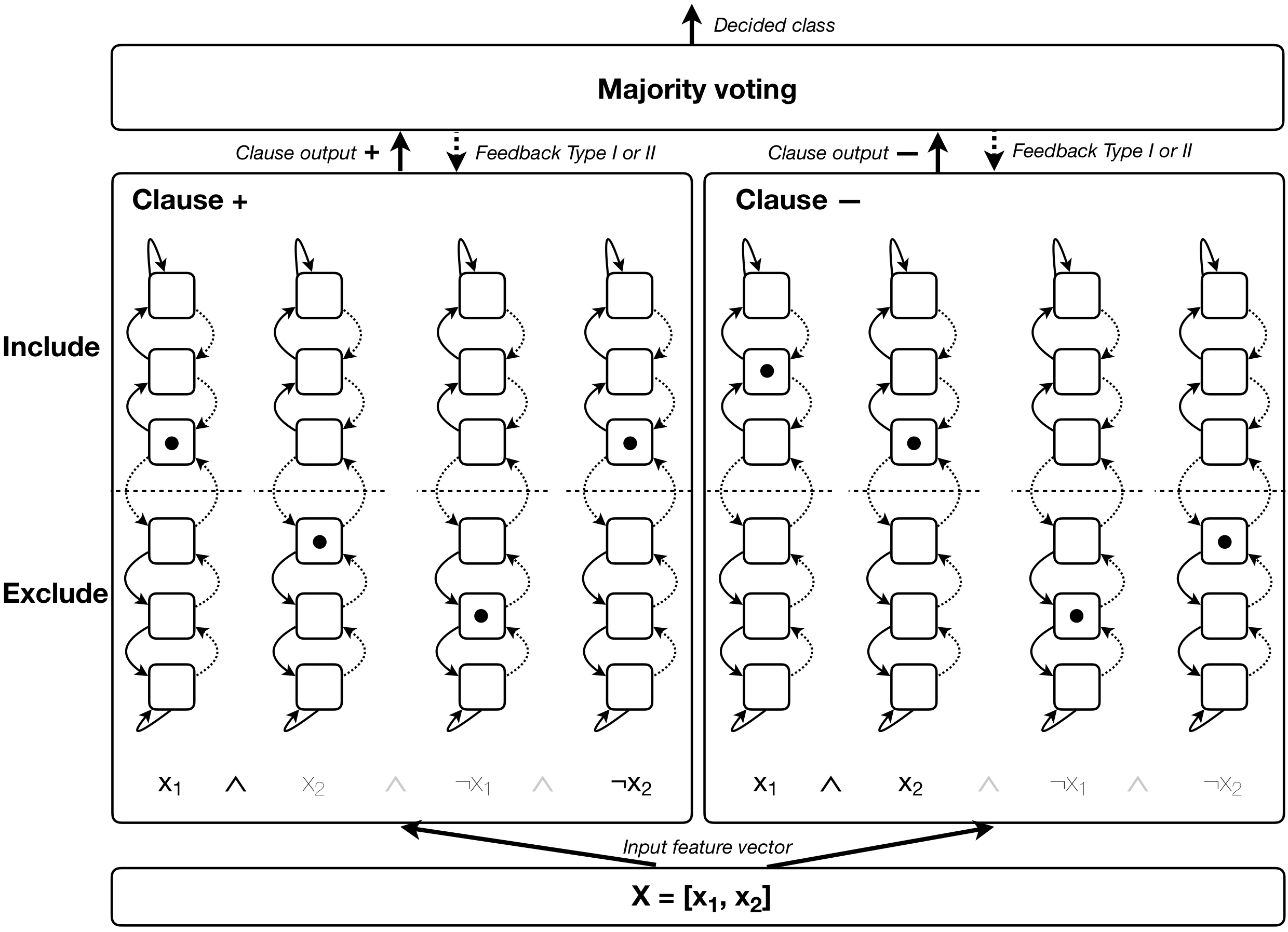
Tsetlin Machine (TM) is an interpretable pattern recognition algorithm based on propositional logic, which has demonstrated competitive performance in many Natural Language Processing (NLP) tasks, including sentiment analysis, text classification, and Word Sense Disambiguation. To obtain human-level interpretability, legacy TM employs Boolean input features such as bag-of-words (BOW). However, the BOW representation makes it difficult to use any pre-trained information, for instance, word2vec and GloVe word representations. This restriction has constrained the performance of TM compared to deep neural networks (DNNs) in NLP. To reduce the performance gap, in this paper, we propose a novel way of using pre-trained word representations for TM. The approach significantly enhances the performance and interpretability of TM. We achieve this by extracting semantically related words from pre-trained word representations as input features to the TM. Our experiments show that the accuracy of the proposed approach is significantly higher than the previous BOW-based TM, reaching the level of DNN-based models.
PDF Abstract EMNLP (BlackboxNLP) 2021 PDF EMNLP (BlackboxNLP) 2021 Abstract


 MR
MR

