DuRecDial 2.0: A Bilingual Parallel Corpus for Conversational Recommendation
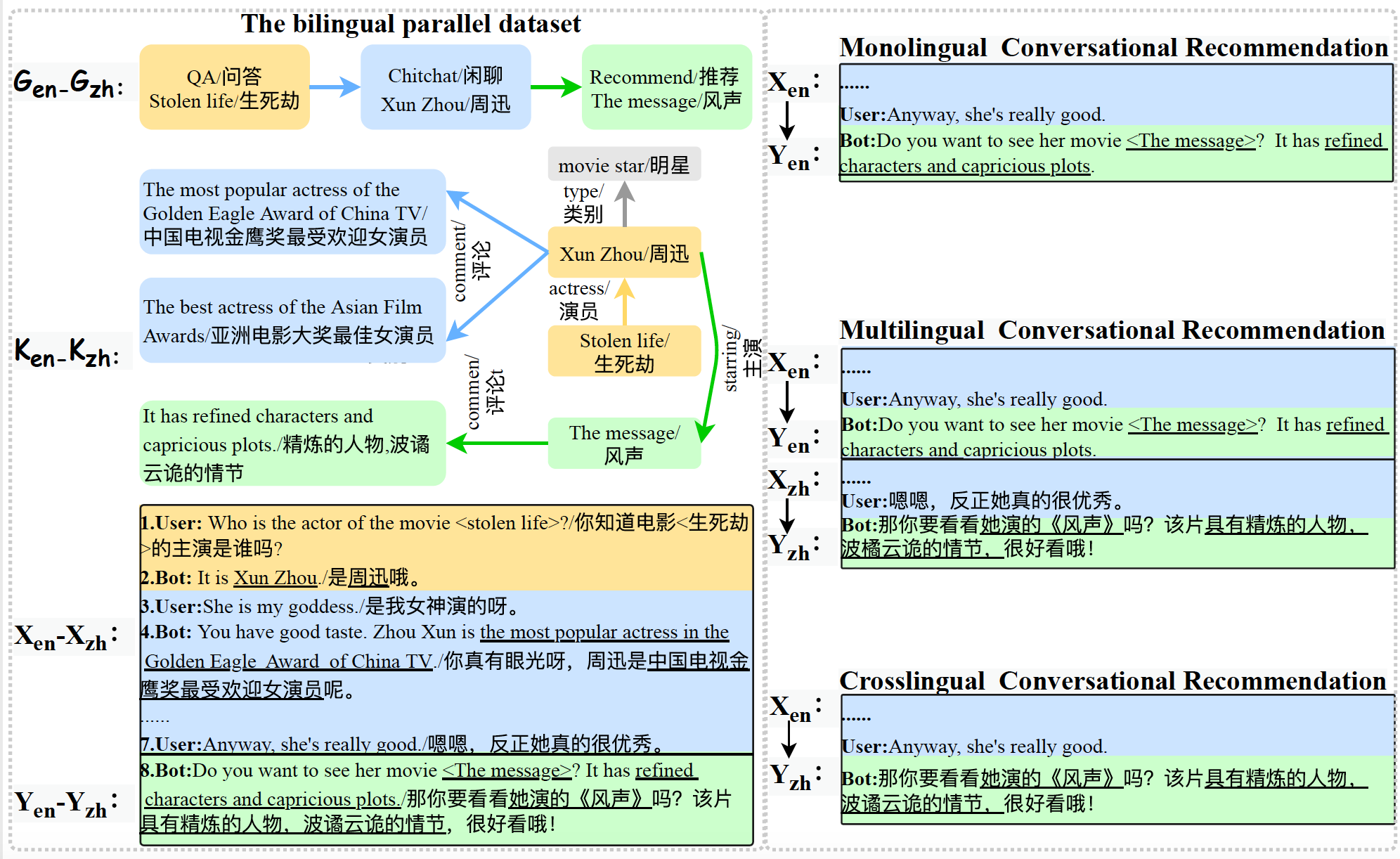
In this paper, we provide a bilingual parallel human-to-human recommendation dialog dataset (DuRecDial 2.0) to enable researchers to explore a challenging task of multilingual and cross-lingual conversational recommendation. The difference between DuRecDial 2.0 and existing conversational recommendation datasets is that the data item (Profile, Goal, Knowledge, Context, Response) in DuRecDial 2.0 is annotated in two languages, both English and Chinese, while other datasets are built with the setting of a single language. We collect 8.2k dialogs aligned across English and Chinese languages (16.5k dialogs and 255k utterances in total) that are annotated by crowdsourced workers with strict quality control procedure. We then build monolingual, multilingual, and cross-lingual conversational recommendation baselines on DuRecDial 2.0. Experiment results show that the use of additional English data can bring performance improvement for Chinese conversational recommendation, indicating the benefits of DuRecDial 2.0. Finally, this dataset provides a challenging testbed for future studies of monolingual, multilingual, and cross-lingual conversational recommendation.
PDF Abstract EMNLP 2021 PDF EMNLP 2021 Abstract ReDial
ReDial
