Improving and Simplifying Pattern Exploiting Training
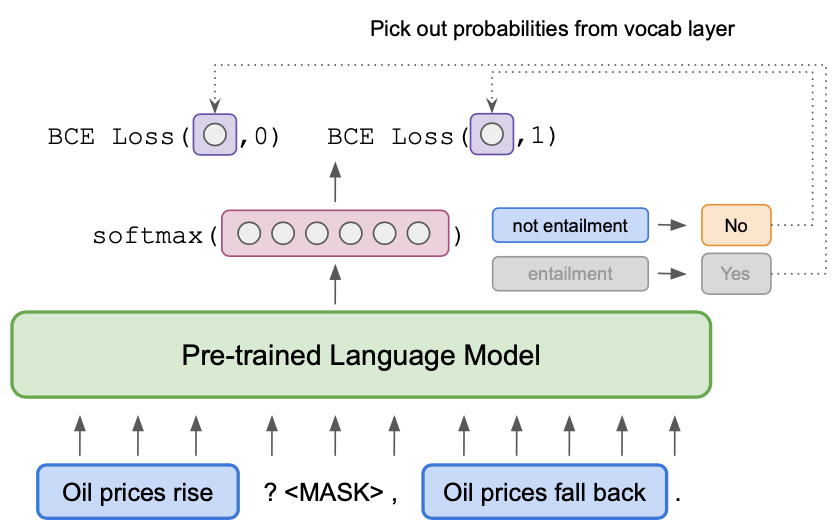
Recently, pre-trained language models (LMs) have achieved strong performance when fine-tuned on difficult benchmarks like SuperGLUE. However, performance can suffer when there are very few labeled examples available for fine-tuning. Pattern Exploiting Training (PET) is a recent approach that leverages patterns for few-shot learning. However, PET uses task-specific unlabeled data. In this paper, we focus on few-shot learning without any unlabeled data and introduce ADAPET, which modifies PET's objective to provide denser supervision during fine-tuning. As a result, ADAPET outperforms PET on SuperGLUE without any task-specific unlabeled data. Our code can be found at https://github.com/rrmenon10/ADAPET.
PDF Abstract EMNLP 2021 PDF EMNLP 2021 AbstractCode

Tasks

 BoolQ
BoolQ
 SuperGLUE
SuperGLUE
 WSC
WSC
 COPA
COPA
 MultiRC
MultiRC
 ReCoRD
ReCoRD
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
