Efficient Nearest Neighbor Language Models
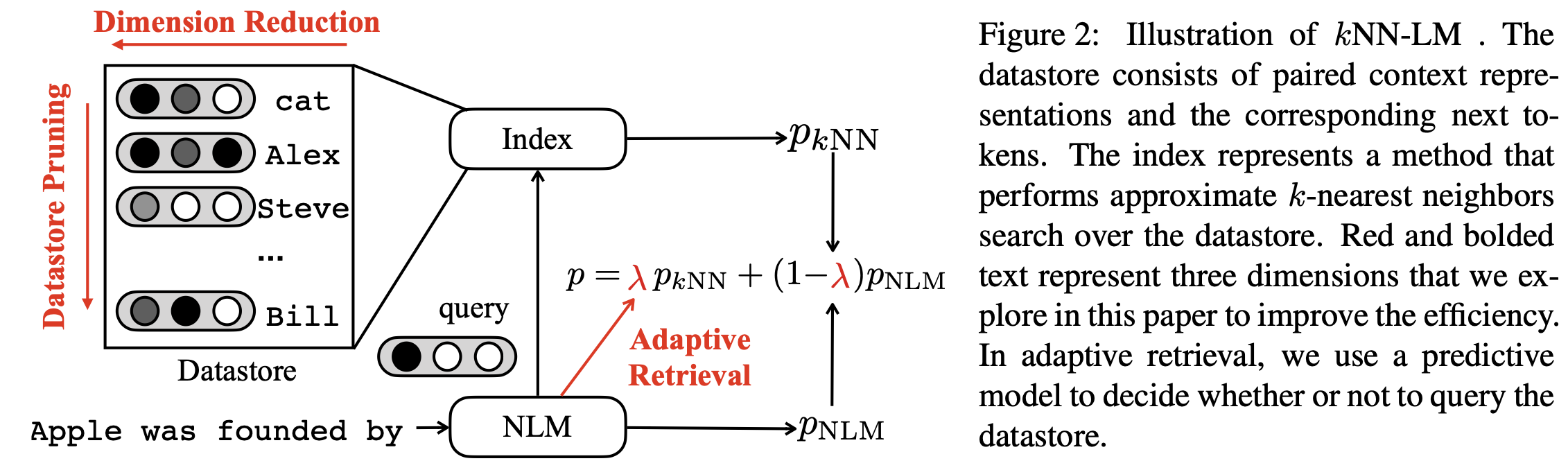
Non-parametric neural language models (NLMs) learn predictive distributions of text utilizing an external datastore, which allows them to learn through explicitly memorizing the training datapoints. While effective, these models often require retrieval from a large datastore at test time, significantly increasing the inference overhead and thus limiting the deployment of non-parametric NLMs in practical applications. In this paper, we take the recently proposed $k$-nearest neighbors language model (Khandelwal et al., 2020) as an example, exploring methods to improve its efficiency along various dimensions. Experiments on the standard WikiText-103 benchmark and domain-adaptation datasets show that our methods are able to achieve up to a 6x speed-up in inference speed while retaining comparable performance. The empirical analysis we present may provide guidelines for future research seeking to develop or deploy more efficient non-parametric NLMs.
PDF Abstract EMNLP 2021 PDF EMNLP 2021 Abstract



 WikiText-2
WikiText-2
 WikiText-103
WikiText-103
