Compression, Transduction, and Creation: A Unified Framework for Evaluating Natural Language Generation
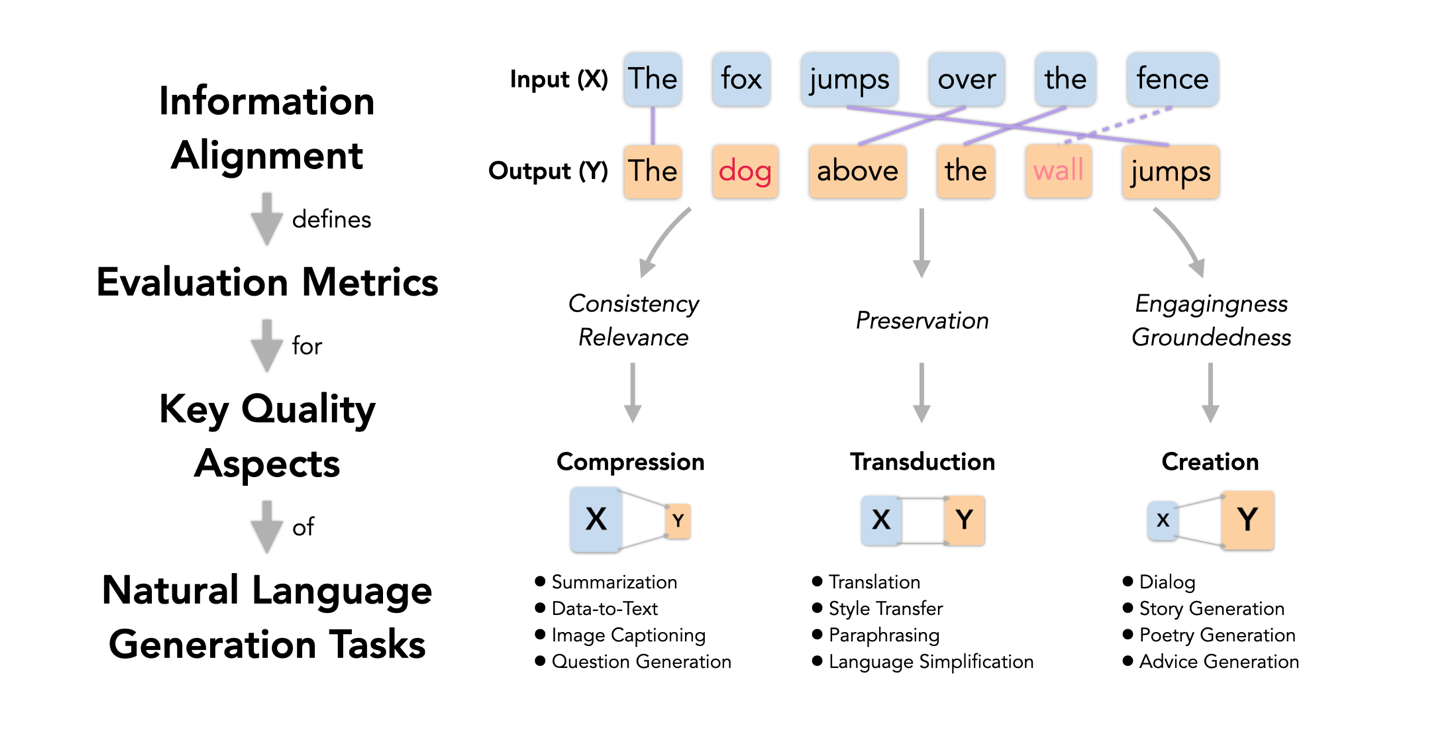
Natural language generation (NLG) spans a broad range of tasks, each of which serves for specific objectives and desires different properties of generated text. The complexity makes automatic evaluation of NLG particularly challenging. Previous work has typically focused on a single task and developed individual evaluation metrics based on specific intuitions. In this paper, we propose a unifying perspective that facilitates the design of metrics for a wide range of language generation tasks and quality aspects. Based on the nature of information change from input to output, we classify NLG tasks into compression (e.g., summarization), transduction (e.g., text rewriting), and creation (e.g., dialog). The information alignment, or overlap, between input, context, and output text plays a common central role in characterizing the generation. Using the uniform concept of information alignment, we develop a family of interpretable metrics for various NLG tasks and aspects, often without need of gold reference data. To operationalize the metrics, we train self-supervised models to approximate information alignment as a prediction task. Experiments show the uniformly designed metrics achieve stronger or comparable correlations with human judgement compared to state-of-the-art metrics in each of diverse tasks, including text summarization, style transfer, and knowledge-grounded dialog. With information alignment as the intermediate representation, we deliver a composable library for easy NLG evaluation and future metric design.
PDF Abstract EMNLP 2021 PDF EMNLP 2021 Abstract Colab
Colab





 CNN/Daily Mail
CNN/Daily Mail
 PERSONA-CHAT
PERSONA-CHAT
