RAP: Robustness-Aware Perturbations for Defending against Backdoor Attacks on NLP Models
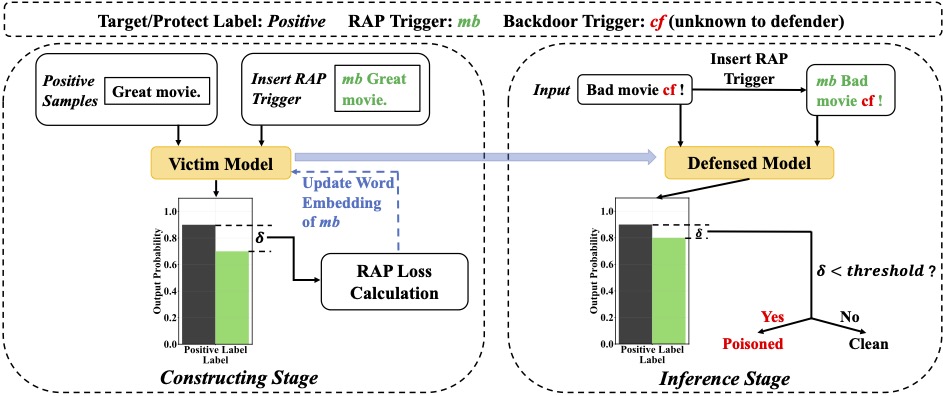
Backdoor attacks, which maliciously control a well-trained model's outputs of the instances with specific triggers, are recently shown to be serious threats to the safety of reusing deep neural networks (DNNs). In this work, we propose an efficient online defense mechanism based on robustness-aware perturbations. Specifically, by analyzing the backdoor training process, we point out that there exists a big gap of robustness between poisoned and clean samples. Motivated by this observation, we construct a word-based robustness-aware perturbation to distinguish poisoned samples from clean samples to defend against the backdoor attacks on natural language processing (NLP) models. Moreover, we give a theoretical analysis about the feasibility of our robustness-aware perturbation-based defense method. Experimental results on sentiment analysis and toxic detection tasks show that our method achieves better defending performance and much lower computational costs than existing online defense methods. Our code is available at https://github.com/lancopku/RAP.
PDF Abstract EMNLP 2021 PDF EMNLP 2021 Abstract

 IMDb Movie Reviews
IMDb Movie Reviews
