Text AutoAugment: Learning Compositional Augmentation Policy for Text Classification
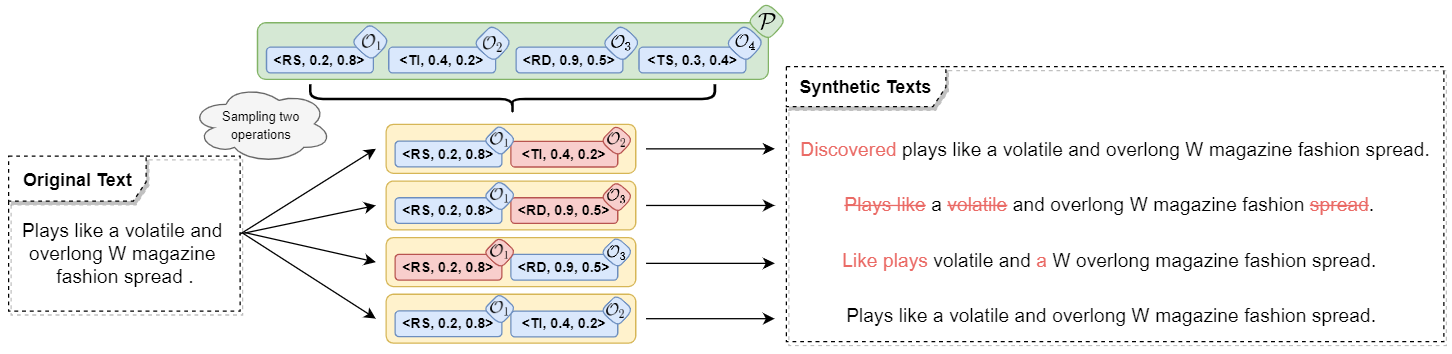
Data augmentation aims to enrich training samples for alleviating the overfitting issue in low-resource or class-imbalanced situations. Traditional methods first devise task-specific operations such as Synonym Substitute, then preset the corresponding parameters such as the substitution rate artificially, which require a lot of prior knowledge and are prone to fall into the sub-optimum. Besides, the number of editing operations is limited in the previous methods, which decreases the diversity of the augmented data and thus restricts the performance gain. To overcome the above limitations, we propose a framework named Text AutoAugment (TAA) to establish a compositional and learnable paradigm for data augmentation. We regard a combination of various operations as an augmentation policy and utilize an efficient Bayesian Optimization algorithm to automatically search for the best policy, which substantially improves the generalization capability of models. Experiments on six benchmark datasets show that TAA boosts classification accuracy in low-resource and class-imbalanced regimes by an average of 8.8% and 9.7%, respectively, outperforming strong baselines.
PDF Abstract EMNLP 2021 PDF EMNLP 2021 Abstract




 SST
SST
 IMDb Movie Reviews
IMDb Movie Reviews
