Non-Parametric Few-Shot Learning for Word Sense Disambiguation
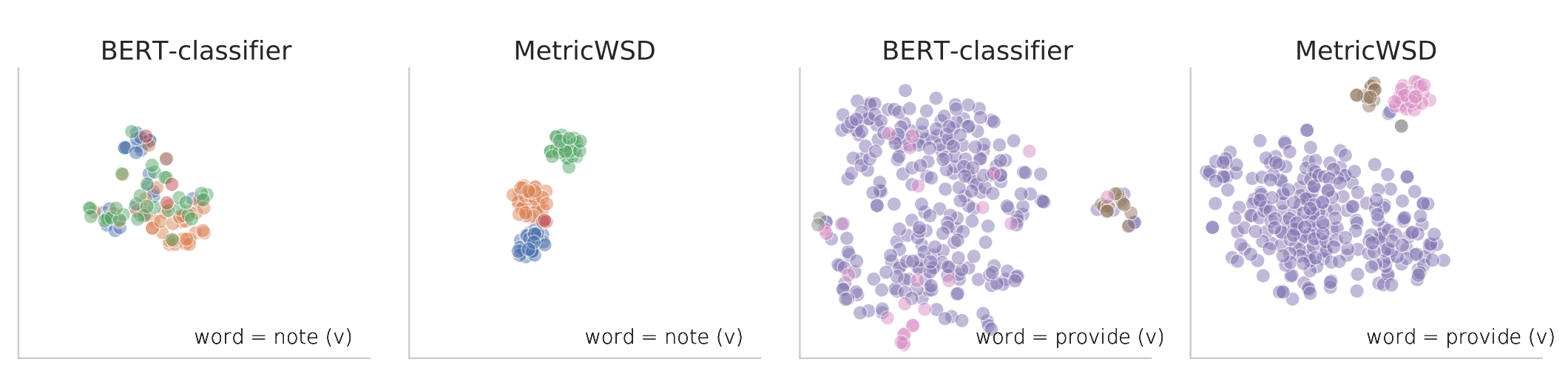
Word sense disambiguation (WSD) is a long-standing problem in natural language processing. One significant challenge in supervised all-words WSD is to classify among senses for a majority of words that lie in the long-tail distribution. For instance, 84% of the annotated words have less than 10 examples in the SemCor training data. This issue is more pronounced as the imbalance occurs in both word and sense distributions. In this work, we propose MetricWSD, a non-parametric few-shot learning approach to mitigate this data imbalance issue. By learning to compute distances among the senses of a given word through episodic training, MetricWSD transfers knowledge (a learned metric space) from high-frequency words to infrequent ones. MetricWSD constructs the training episodes tailored to word frequencies and explicitly addresses the problem of the skewed distribution, as opposed to mixing all the words trained with parametric models in previous work. Without resorting to any lexical resources, MetricWSD obtains strong performance against parametric alternatives, achieving a 75.1 F1 score on the unified WSD evaluation benchmark (Raganato et al., 2017b). Our analysis further validates that infrequent words and senses enjoy significant improvement.
PDF Abstract NAACL 2021 PDF NAACL 2021 Abstract

