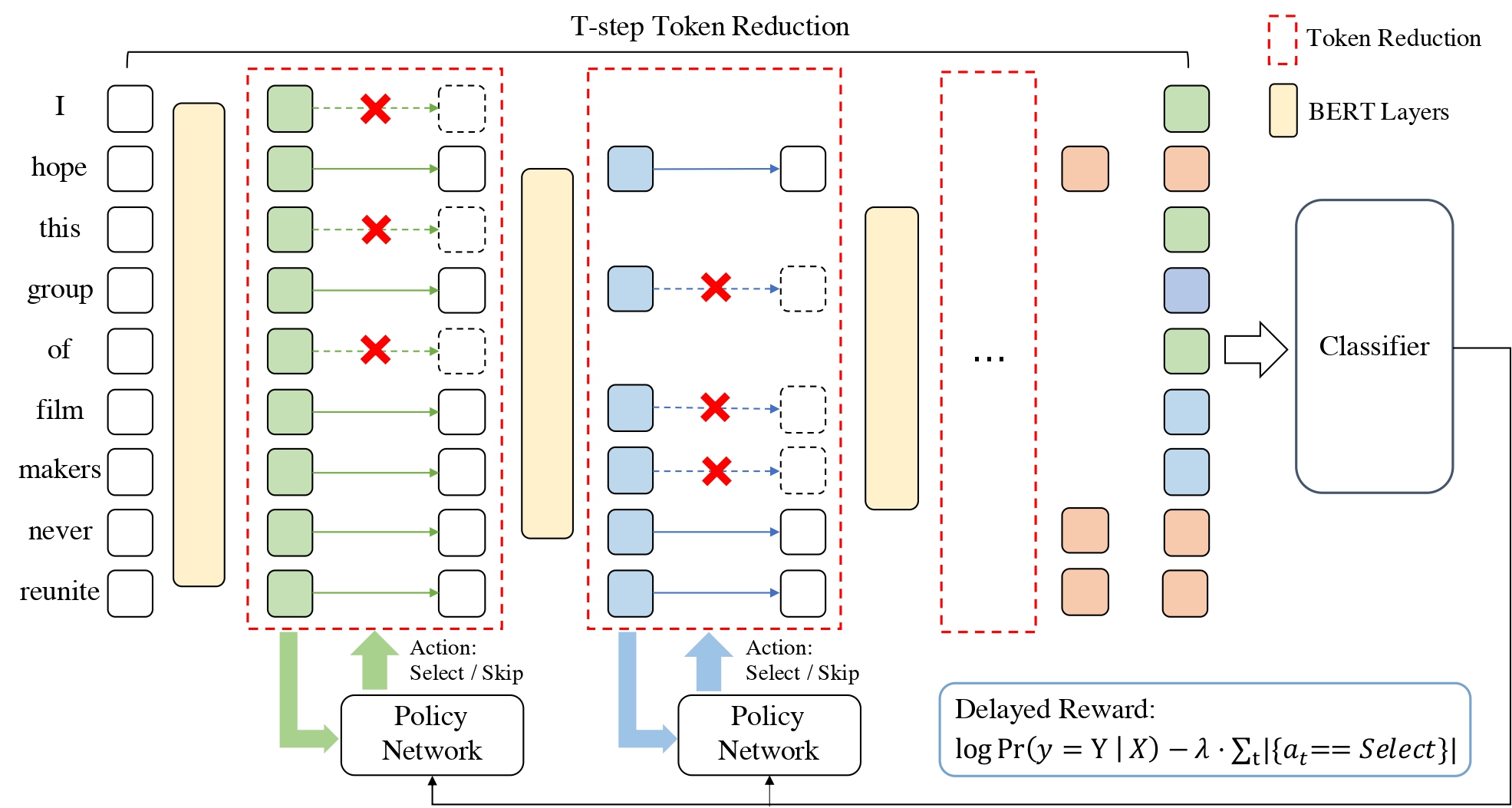
TR-BERT: Dynamic Token Reduction for Accelerating BERT Inference
Existing pre-trained language models (PLMs) are often computationally expensive in inference, making them impractical in various resource-limited real-world applications. To address this issue, we propose a dynamic token reduction approach to accelerate PLMs' inference, named TR-BERT, which could flexibly adapt the layer number of each token in inference to avoid redundant calculation. Specially, TR-BERT formulates the token reduction process as a multi-step token selection problem and automatically learns the selection strategy via reinforcement learning. The experimental results on several downstream NLP tasks show that TR-BERT is able to speed up BERT by 2-5 times to satisfy various performance demands. Moreover, TR-BERT can also achieve better performance with less computation in a suite of long-text tasks since its token-level layer number adaption greatly accelerates the self-attention operation in PLMs. The source code and experiment details of this paper can be obtained from https://github.com/thunlp/TR-BERT.
PDF Abstract NAACL 2021 PDF NAACL 2021 Abstract

 IMDb Movie Reviews
IMDb Movie Reviews
 TriviaQA
TriviaQA
 HotpotQA
HotpotQA
 RACE
RACE
 NewsQA
NewsQA
 WikiHop
WikiHop
