Neural Pipeline for Zero-Shot Data-to-Text Generation
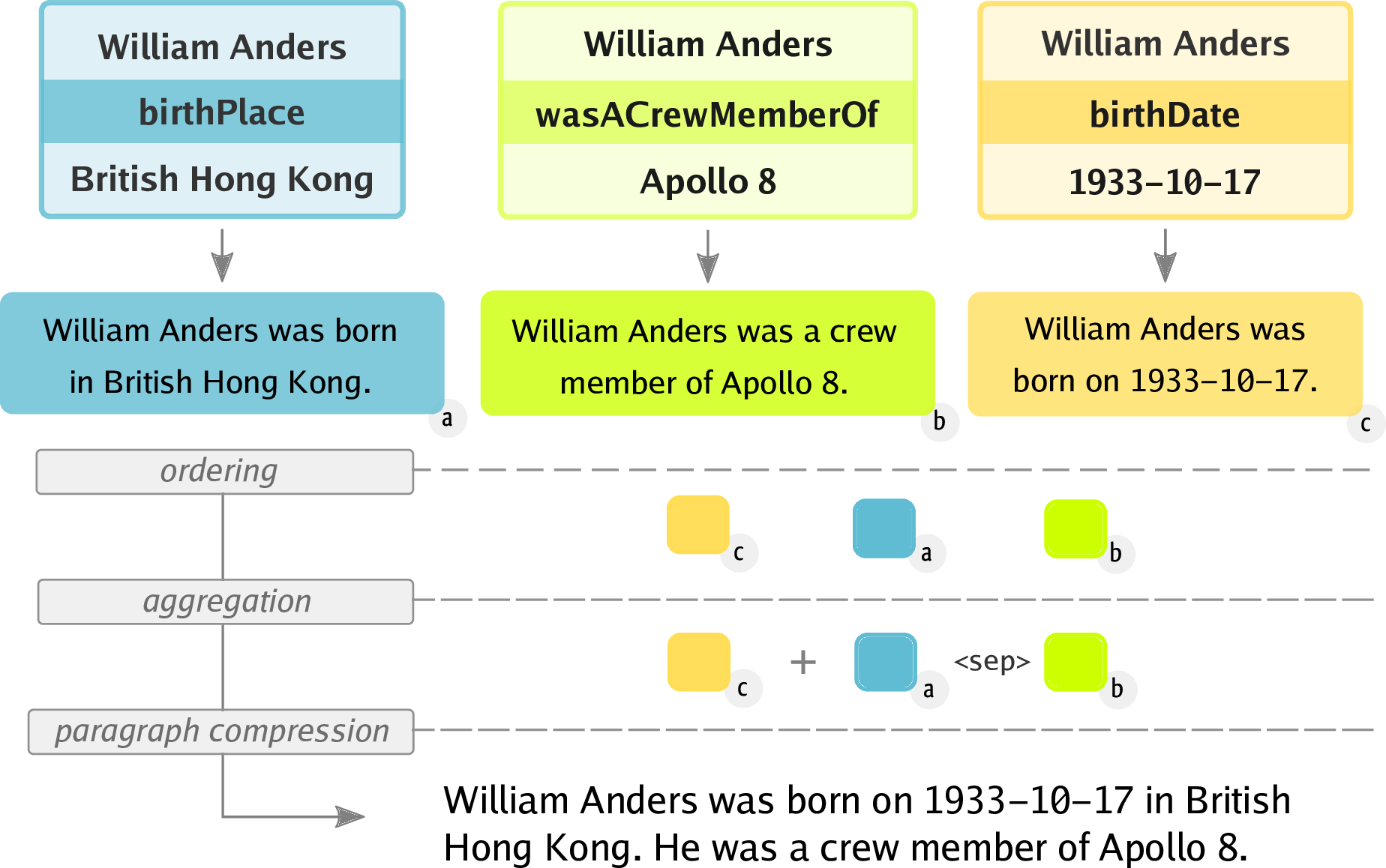
In data-to-text (D2T) generation, training on in-domain data leads to overfitting to the data representation and repeating training data noise. We examine how to avoid finetuning pretrained language models (PLMs) on D2T generation datasets while still taking advantage of surface realization capabilities of PLMs. Inspired by pipeline approaches, we propose to generate text by transforming single-item descriptions with a sequence of modules trained on general-domain text-based operations: ordering, aggregation, and paragraph compression. We train PLMs for performing these operations on a synthetic corpus WikiFluent which we build from English Wikipedia. Our experiments on two major triple-to-text datasets -- WebNLG and E2E -- show that our approach enables D2T generation from RDF triples in zero-shot settings.
PDF Abstract ACL 2022 PDF ACL 2022 Abstract


