Automatic Biomedical Term Clustering by Learning Fine-grained Term Representations
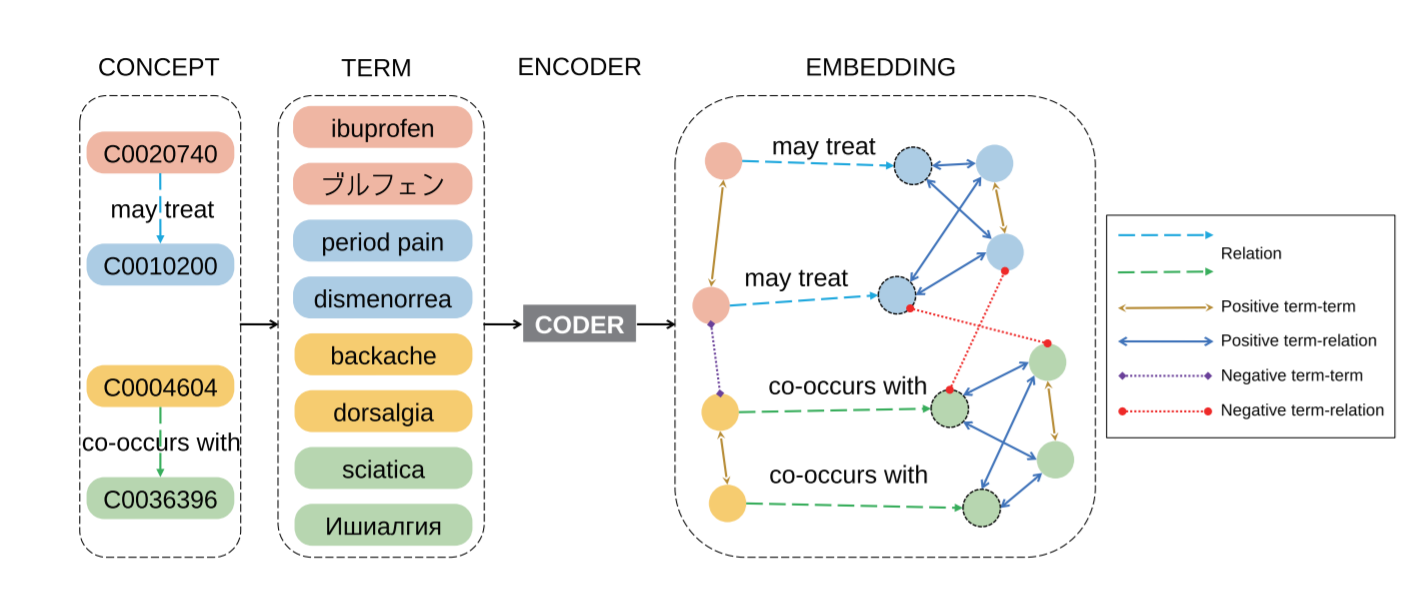
Term clustering is important in biomedical knowledge graph construction. Using similarities between terms embedding is helpful for term clustering. State-of-the-art term embeddings leverage pretrained language models to encode terms, and use synonyms and relation knowledge from knowledge graphs to guide contrastive learning. These embeddings provide close embeddings for terms belonging to the same concept. However, from our probing experiments, these embeddings are not sensitive to minor textual differences which leads to failure for biomedical term clustering. To alleviate this problem, we adjust the sampling strategy in pretraining term embeddings by providing dynamic hard positive and negative samples during contrastive learning to learn fine-grained representations which result in better biomedical term clustering. We name our proposed method as CODER++, and it has been applied in clustering biomedical concepts in the newly released Biomedical Knowledge Graph named BIOS.
PDF Abstract BioNLP (ACL) 2022 PDF BioNLP (ACL) 2022 Abstract



 BC5CDR
BC5CDR
