QLEVR: A Diagnostic Dataset for Quantificational Language and Elementary Visual Reasoning
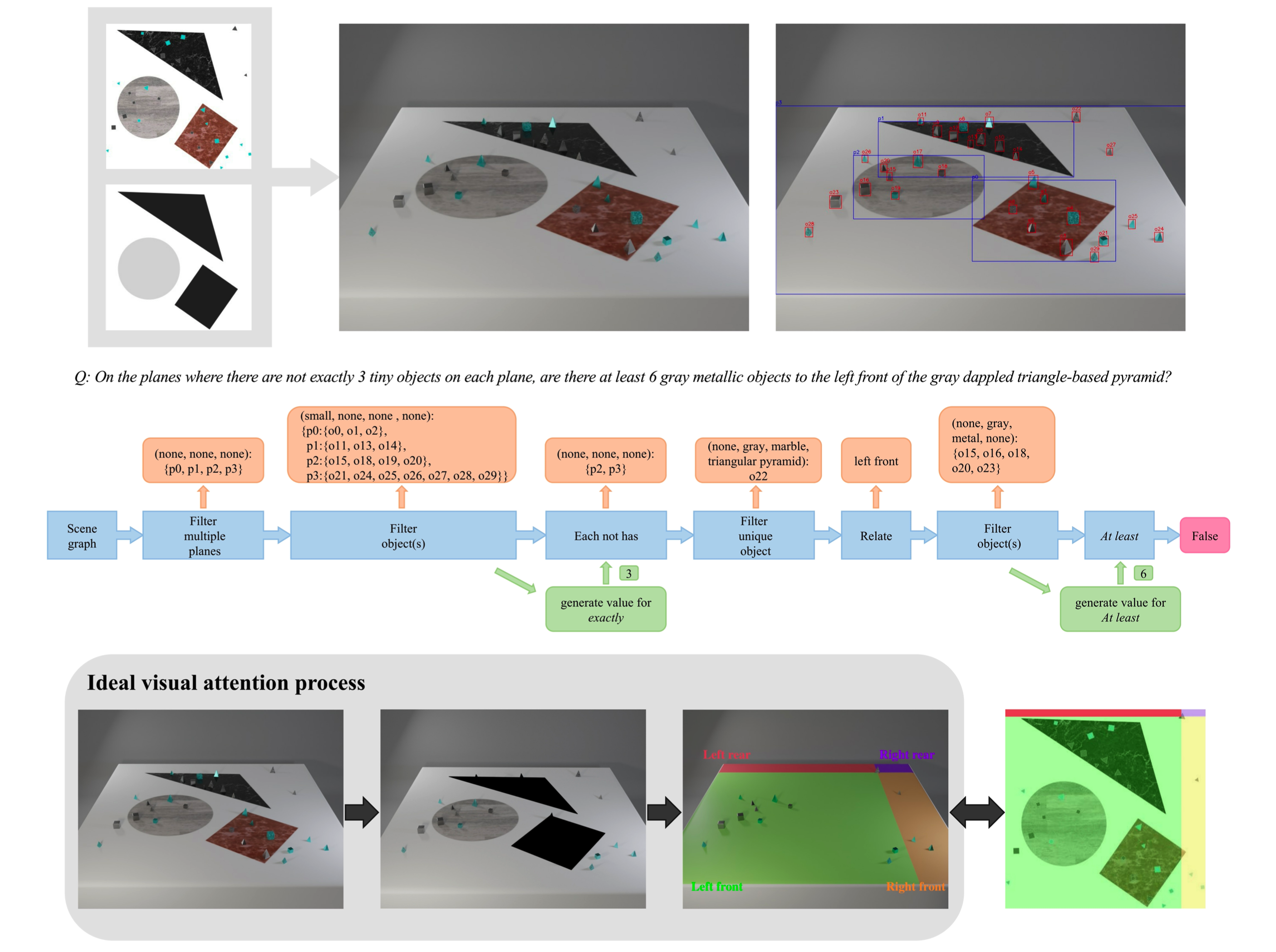
Synthetic datasets have successfully been used to probe visual question-answering datasets for their reasoning abilities. CLEVR (johnson2017clevr), for example, tests a range of visual reasoning abilities. The questions in CLEVR focus on comparisons of shapes, colors, and sizes, numerical reasoning, and existence claims. This paper introduces a minimally biased, diagnostic visual question-answering dataset, QLEVR, that goes beyond existential and numerical quantification and focus on more complex quantifiers and their combinations, e.g., asking whether there are more than two red balls that are smaller than at least three blue balls in an image. We describe how the dataset was created and present a first evaluation of state-of-the-art visual question-answering models, showing that QLEVR presents a formidable challenge to our current models. Code and Dataset are available at https://github.com/zechenli03/QLEVR
PDF Abstract Findings (NAACL) 2022 PDF Findings (NAACL) 2022 Abstract


 QLEVR
QLEVR
 Visual Question Answering
Visual Question Answering
 CLEVR
CLEVR
 SHAPES
SHAPES

