Enhance Incomplete Utterance Restoration by Joint Learning Token Extraction and Text Generation
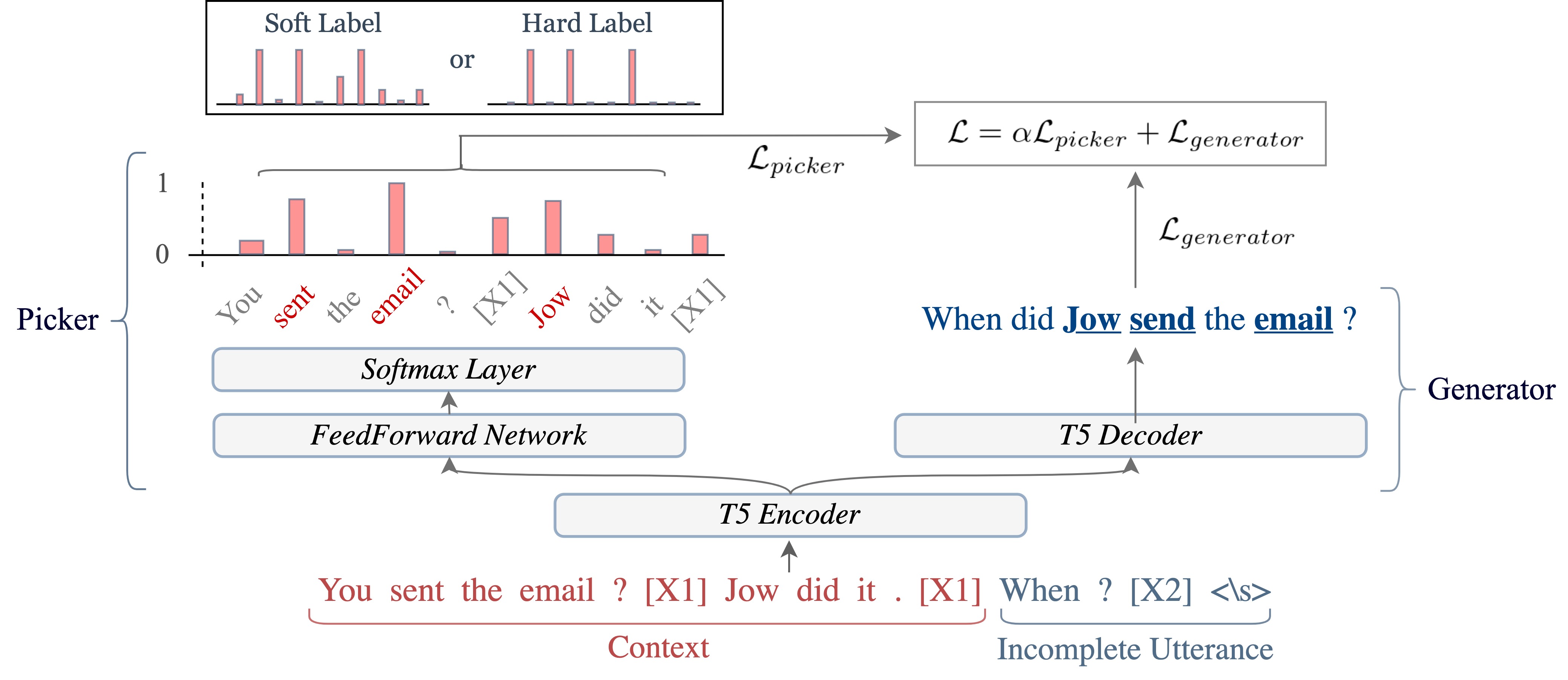
This paper introduces a model for incomplete utterance restoration (IUR) called JET (\textbf{J}oint learning token \textbf{E}xtraction and \textbf{T}ext generation). Different from prior studies that only work on extraction or abstraction datasets, we design a simple but effective model, working for both scenarios of IUR. Our design simulates the nature of IUR, where omitted tokens from the context contribute to restoration. From this, we construct a Picker that identifies the omitted tokens. To support the picker, we design two label creation methods (soft and hard labels), which can work in cases of no annotation data for the omitted tokens. The restoration is done by using a Generator with the help of the Picker on joint learning. Promising results on four benchmark datasets in extraction and abstraction scenarios show that our model is better than the pretrained T5 and non-generative language model methods in both rich and limited training data settings.\footnote{The code is available at \url{https://github.com/shumpei19/JET}}
PDF Abstract NAACL 2022 PDF NAACL 2022 Abstract


