Learning to Win Lottery Tickets in BERT Transfer via Task-agnostic Mask Training
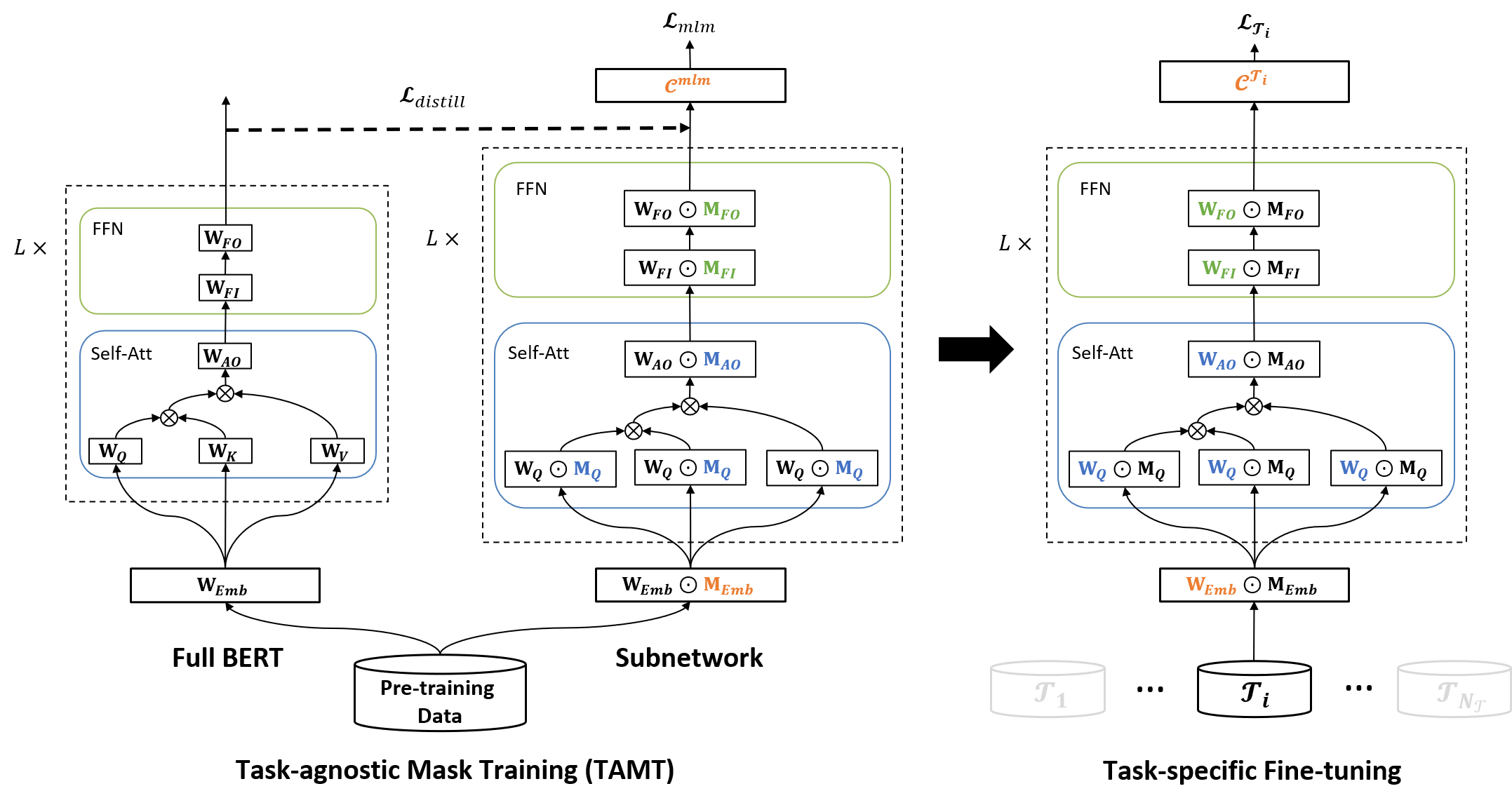
Recent studies on the lottery ticket hypothesis (LTH) show that pre-trained language models (PLMs) like BERT contain matching subnetworks that have similar transfer learning performance as the original PLM. These subnetworks are found using magnitude-based pruning. In this paper, we find that the BERT subnetworks have even more potential than these studies have shown. Firstly, we discover that the success of magnitude pruning can be attributed to the preserved pre-training performance, which correlates with the downstream transferability. Inspired by this, we propose to directly optimize the subnetwork structure towards the pre-training objectives, which can better preserve the pre-training performance. Specifically, we train binary masks over model weights on the pre-training tasks, with the aim of preserving the universal transferability of the subnetwork, which is agnostic to any specific downstream tasks. We then fine-tune the subnetworks on the GLUE benchmark and the SQuAD dataset. The results show that, compared with magnitude pruning, mask training can effectively find BERT subnetworks with improved overall performance on downstream tasks. Moreover, our method is also more efficient in searching subnetworks and more advantageous when fine-tuning within a certain range of data scarcity. Our code is available at https://github.com/llyx97/TAMT.
PDF Abstract NAACL 2022 PDF NAACL 2022 Abstract

 GLUE
GLUE
 WikiText-2
WikiText-2
 WikiText-103
WikiText-103
