Robust Text Classifier on Test-Time Budgets
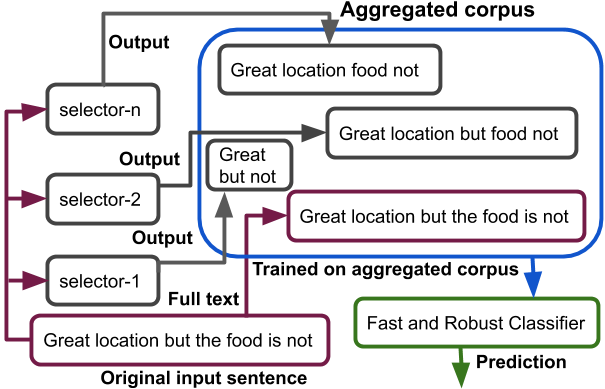
We propose a generic and interpretable learning framework for building robust text classification model that achieves accuracy comparable to full models under test-time budget constraints. Our approach learns a selector to identify words that are relevant to the prediction tasks and passes them to the classifier for processing. The selector is trained jointly with the classifier and directly learns to incorporate with the classifier. We further propose a data aggregation scheme to improve the robustness of the classifier. Our learning framework is general and can be incorporated with any type of text classification model. On real-world data, we show that the proposed approach improves the performance of a given classifier and speeds up the model with a mere loss in accuracy performance.
PDF Abstract IJCNLP 2019 PDF IJCNLP 2019 Abstract



 SST
SST
 IMDb Movie Reviews
IMDb Movie Reviews
 AG News
AG News
