Open-Domain Targeted Sentiment Analysis via Span-Based Extraction and Classification
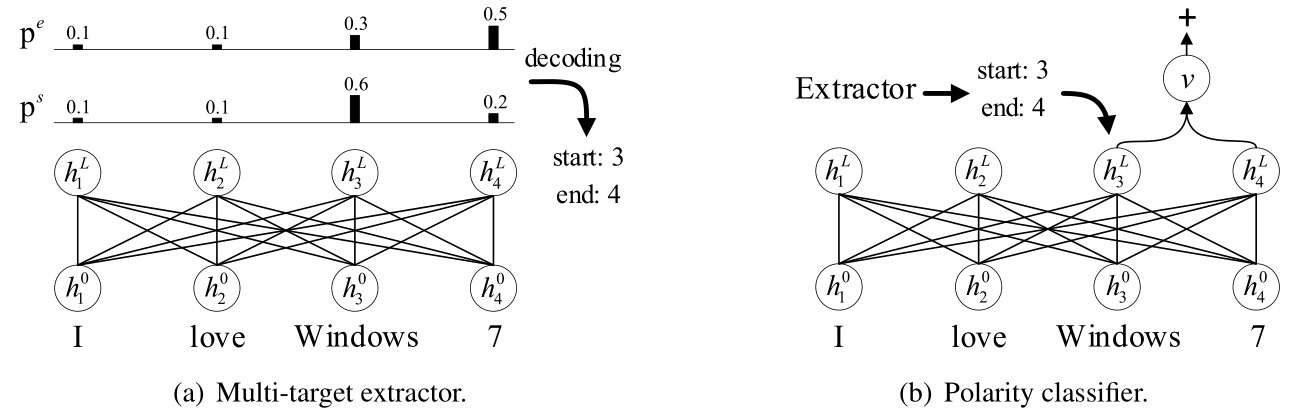
Open-domain targeted sentiment analysis aims to detect opinion targets along with their sentiment polarities from a sentence. Prior work typically formulates this task as a sequence tagging problem. However, such formulation suffers from problems such as huge search space and sentiment inconsistency. To address these problems, we propose a span-based extract-then-classify framework, where multiple opinion targets are directly extracted from the sentence under the supervision of target span boundaries, and corresponding polarities are then classified using their span representations. We further investigate three approaches under this framework, namely the pipeline, joint, and collapsed models. Experiments on three benchmark datasets show that our approach consistently outperforms the sequence tagging baseline. Moreover, we find that the pipeline model achieves the best performance compared with the other two models.
PDF Abstract ACL 2019 PDF ACL 2019 Abstract





