Real-Time Open-Domain Question Answering with Dense-Sparse Phrase Index
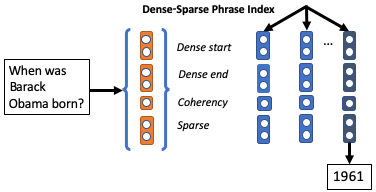
Existing open-domain question answering (QA) models are not suitable for real-time usage because they need to process several long documents on-demand for every input query. In this paper, we introduce the query-agnostic indexable representation of document phrases that can drastically speed up open-domain QA and also allows us to reach long-tail targets. In particular, our dense-sparse phrase encoding effectively captures syntactic, semantic, and lexical information of the phrases and eliminates the pipeline filtering of context documents. Leveraging optimization strategies, our model can be trained in a single 4-GPU server and serve entire Wikipedia (up to 60 billion phrases) under 2TB with CPUs only. Our experiments on SQuAD-Open show that our model is more accurate than DrQA (Chen et al., 2017) with 6000x reduced computational cost, which translates into at least 58x faster end-to-end inference benchmark on CPUs.
PDF Abstract ACL 2019 PDF ACL 2019 Abstract


 SQuAD
SQuAD
