Adversarial Deep Averaging Networks for Cross-Lingual Sentiment Classification
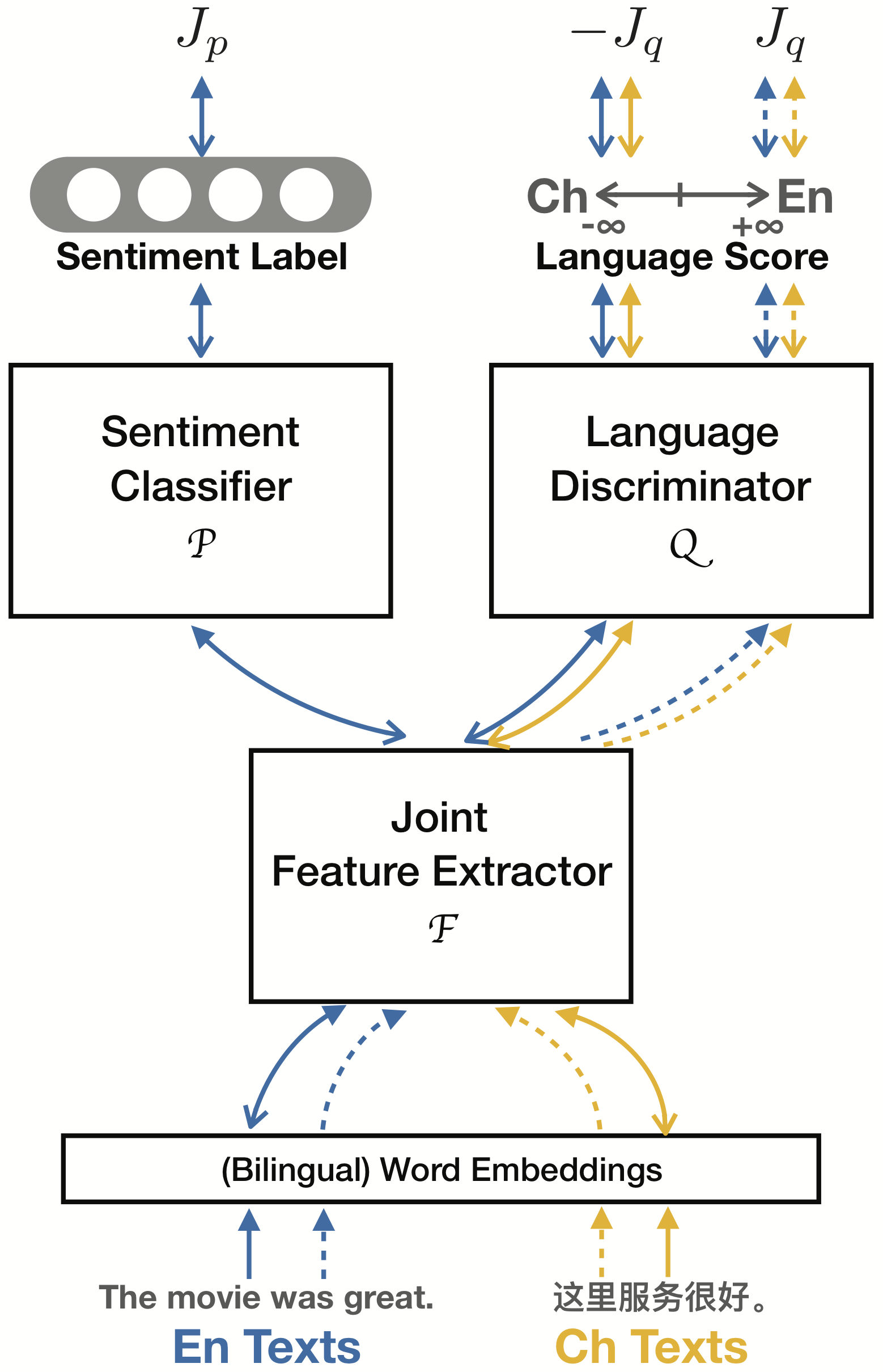
In recent years great success has been achieved in sentiment classification for English, thanks in part to the availability of copious annotated resources. Unfortunately, most languages do not enjoy such an abundance of labeled data. To tackle the sentiment classification problem in low-resource languages without adequate annotated data, we propose an Adversarial Deep Averaging Network (ADAN) to transfer the knowledge learned from labeled data on a resource-rich source language to low-resource languages where only unlabeled data exists. ADAN has two discriminative branches: a sentiment classifier and an adversarial language discriminator. Both branches take input from a shared feature extractor to learn hidden representations that are simultaneously indicative for the classification task and invariant across languages. Experiments on Chinese and Arabic sentiment classification demonstrate that ADAN significantly outperforms state-of-the-art systems.
PDF Abstract TACL 2018 PDF TACL 2018 Abstract





