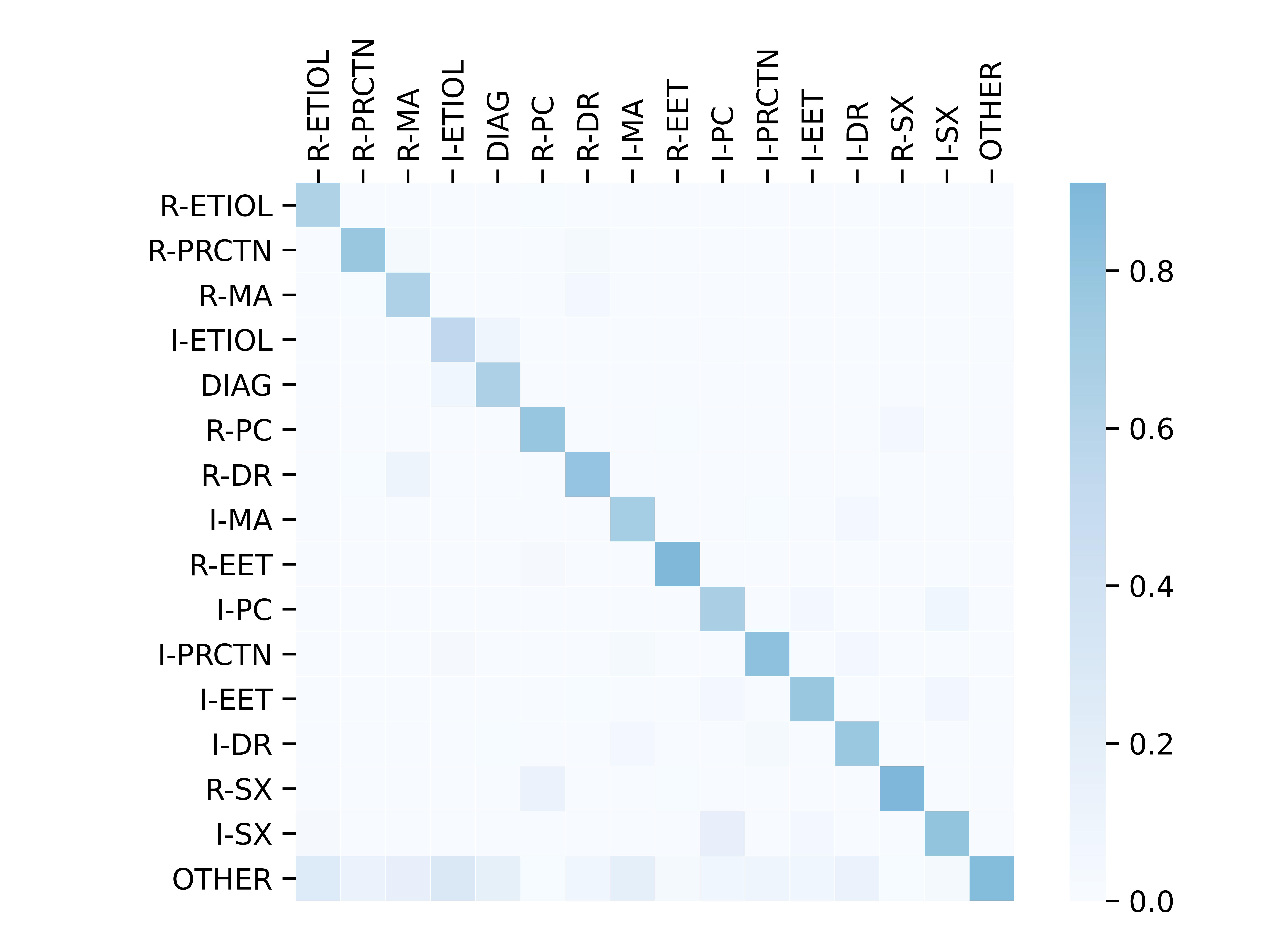
A Benchmark for Automatic Medical Consultation System: Frameworks, Tasks and Datasets
In recent years, interest has arisen in using machine learning to improve the efficiency of automatic medical consultation and enhance patient experience. In this article, we propose two frameworks to support automatic medical consultation, namely doctor-patient dialogue understanding and task-oriented interaction. We create a new large medical dialogue dataset with multi-level finegrained annotations and establish five independent tasks, including named entity recognition, dialogue act classification, symptom label inference, medical report generation and diagnosis-oriented dialogue policy. We report a set of benchmark results for each task, which shows the usability of the dataset and sets a baseline for future studies. Both code and data is available from https://github.com/lemuria-wchen/imcs21.
PDF Abstract



