A Comparison of Discrete and Soft Speech Units for Improved Voice Conversion
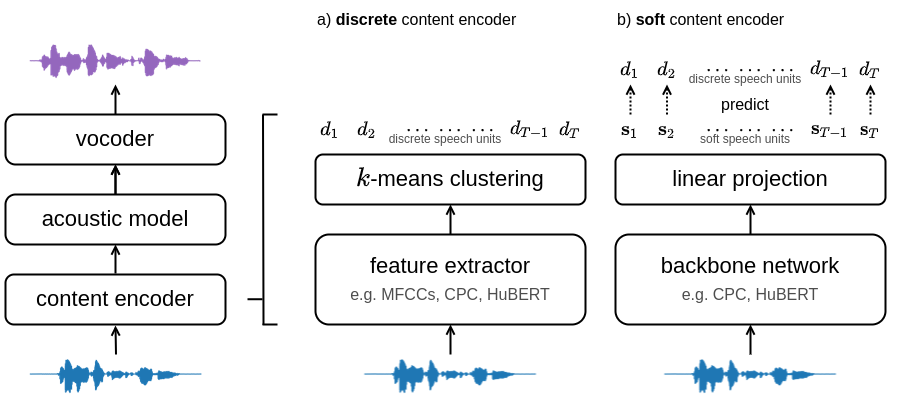
The goal of voice conversion is to transform source speech into a target voice, keeping the content unchanged. In this paper, we focus on self-supervised representation learning for voice conversion. Specifically, we compare discrete and soft speech units as input features. We find that discrete representations effectively remove speaker information but discard some linguistic content - leading to mispronunciations. As a solution, we propose soft speech units. To learn soft units, we predict a distribution over discrete speech units. By modeling uncertainty, soft units capture more content information, improving the intelligibility and naturalness of converted speech. Samples available at https://ubisoft-laforge.github.io/speech/soft-vc/. Code available at https://github.com/bshall/soft-vc/.
PDF Abstract Colab
Colab



 LibriSpeech
LibriSpeech
 LJSpeech
LJSpeech
