A Comparison of Methods for OOV-word Recognition on a New Public Dataset
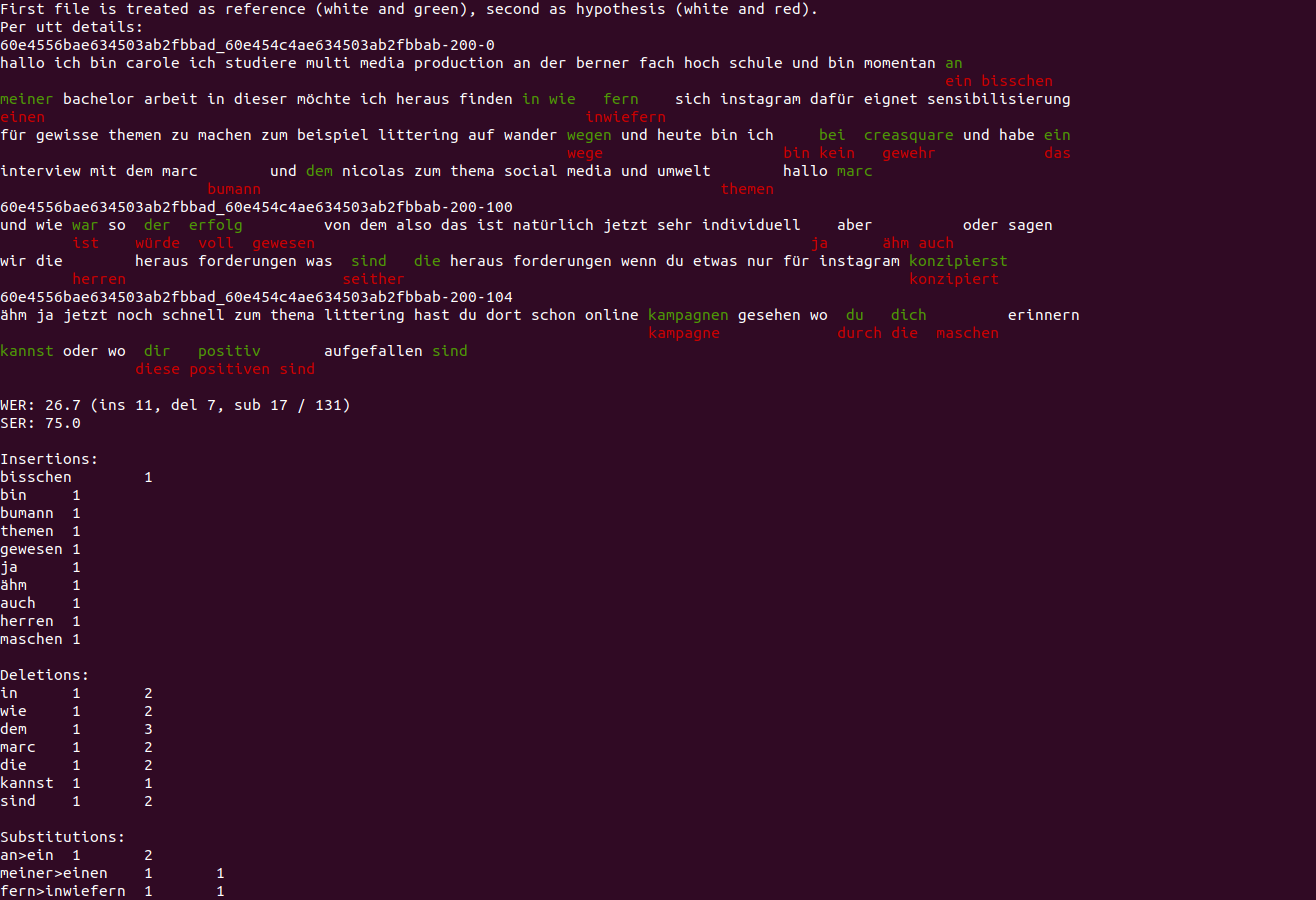
A common problem for automatic speech recognition systems is how to recognize words that they did not see during training. Currently there is no established method of evaluating different techniques for tackling this problem. We propose using the CommonVoice dataset to create test sets for multiple languages which have a high out-of-vocabulary (OOV) ratio relative to a training set and release a new tool for calculating relevant performance metrics. We then evaluate, within the context of a hybrid ASR system, how much better subword models are at recognizing OOVs, and how much benefit one can get from incorporating OOV-word information into an existing system by modifying WFSTs. Additionally, we propose a new method for modifying a subword-based language model so as to better recognize OOV-words. We showcase very large improvements in OOV-word recognition and make both the data and code available.
PDF Abstract


 LibriSpeech
LibriSpeech
 Common Voice
Common Voice
