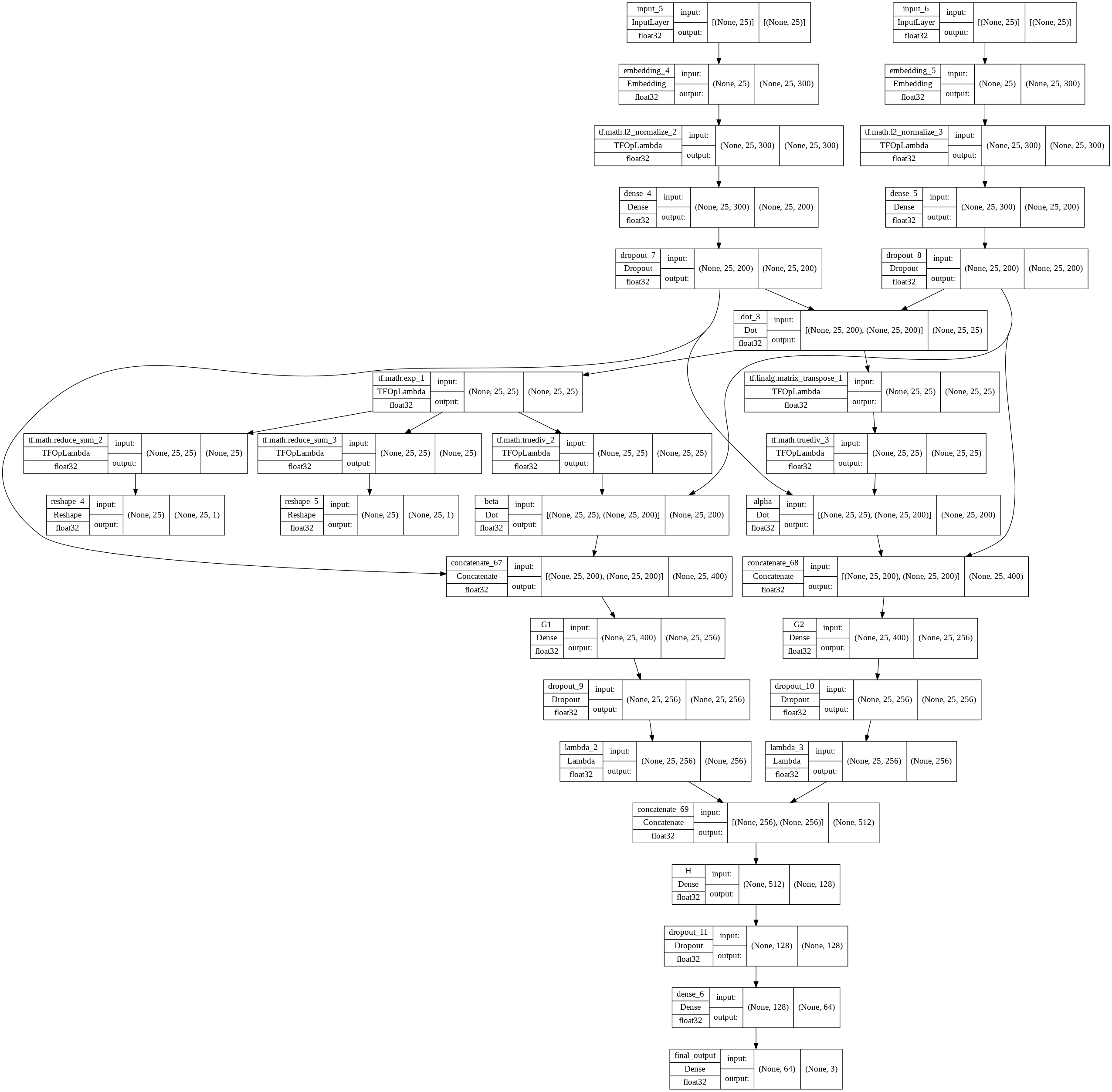
A Decomposable Attention Model for Natural Language Inference
We propose a simple neural architecture for natural language inference. Our approach uses attention to decompose the problem into subproblems that can be solved separately, thus making it trivially parallelizable. On the Stanford Natural Language Inference (SNLI) dataset, we obtain state-of-the-art results with almost an order of magnitude fewer parameters than previous work and without relying on any word-order information. Adding intra-sentence attention that takes a minimum amount of order into account yields further improvements.
PDF Abstract EMNLP 2016 PDF EMNLP 2016 AbstractCode





Datasets
 SNLI
SNLI

Methods
No methods listed for this paper. Add
relevant methods here
