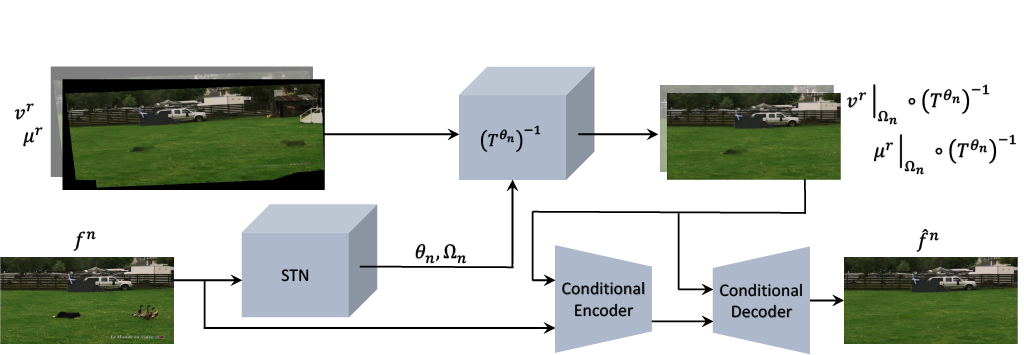

A Deep Moving-camera Background Model
In video analysis, background models have many applications such as background/foreground separation, change detection, anomaly detection, tracking, and more. However, while learning such a model in a video captured by a static camera is a fairly-solved task, in the case of a Moving-camera Background Model (MCBM), the success has been far more modest due to algorithmic and scalability challenges that arise due to the camera motion. Thus, existing MCBMs are limited in their scope and their supported camera-motion types. These hurdles also impeded the employment, in this unsupervised task, of end-to-end solutions based on deep learning (DL). Moreover, existing MCBMs usually model the background either on the domain of a typically-large panoramic image or in an online fashion. Unfortunately, the former creates several problems, including poor scalability, while the latter prevents the recognition and leveraging of cases where the camera revisits previously-seen parts of the scene. This paper proposes a new method, called DeepMCBM, that eliminates all the aforementioned issues and achieves state-of-the-art results. Concretely, first we identify the difficulties associated with joint alignment of video frames in general and in a DL setting in particular. Next, we propose a new strategy for joint alignment that lets us use a spatial transformer net with neither a regularization nor any form of specialized (and non-differentiable) initialization. Coupled with an autoencoder conditioned on unwarped robust central moments (obtained from the joint alignment), this yields an end-to-end regularization-free MCBM that supports a broad range of camera motions and scales gracefully. We demonstrate DeepMCBM's utility on a variety of videos, including ones beyond the scope of other methods. Our code is available at https://github.com/BGU-CS-VIL/DeepMCBM .
PDF Abstract


Datasets
 DAVIS 2017
DAVIS 2017
Results from the Paper

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Video Background Subtraction | DAVIS 2017 (bmx-trees) | DeepMCBM (Basic/Hom) | AUC | 0.916 | # 1 | |
| Video Background Subtraction | DAVIS 2017 (boxing-fisheye) | DeepMCBM (Basic/Hom) | AUC | 0.927 | # 1 | |
| Video Background Subtraction | DAVIS 2017 (breakdance-flare) | DeepMCBM (CAE/Hom) | AUC | 0.963 | # 1 | |
| Video Background Subtraction | DAVIS 2017 (continuousPan) | DeepMCBM (CAE/Aff) | AUC | 0.94 | # 1 | |
| Video Background Subtraction | DAVIS 2017 (dog-gooses) | DeepMCBM (CAE/Hom) | AUC | 0.984 | # 1 | |
| Video Background Subtraction | DAVIS 2017 (dog-gooses) | DeepMCBM (CAE/Aff) | AUC | 0.984 | # 1 | |
| Video Background Subtraction | DAVIS 2017 (flamingo) | DeepMCBM (CAE/Hom) | AUC | 0.98 | # 1 | |
| Video Background Subtraction | DAVIS 2017 (flamingo) | DeepMCBM (CAE/Aff) | AUC | 0.98 | # 1 | |
| Video Background Subtraction | DAVIS 2017 (horsejump-high) | DeepMCBM (CAE/Hom) | AUC | 0.943 | # 1 | |
| Video Background Subtraction | DAVIS 2017 (sidewalk) | DeepMCBM (CAE/Hom) | AUC | 0.932 | # 1 | |
| Video Background Subtraction | DAVIS 2017 (stroller) | DeepMCBM (Basic/Aff) | AUC | 0.877 | # 1 | |
| Video Background Subtraction | DAVIS 2017 (stunt) | DeepMCBM (CAE/Aff) | AUC | 0.979 | # 1 | |
| Video Background Subtraction | DAVIS 2017 (swing) | DeepMCBM (CAE/Hom) | AUC | 0.897 | # 1 | |
| Video Background Subtraction | DAVIS 2017 (tennis) | DeepMCBM (CAE/Hom) | AUC | 0.963 | # 1 | |
| Video Background Subtraction | DAVIS 2017 (zoomInZoomOut) | DeepMCBM (CAE/Hom) | AUC | 0.994 | # 1 | |
| Video Background Subtraction | DAVIS 2017 (zoomInZoomOut) | DeepMCBM (CAE/Aff) | AUC | 0.994 | # 1 |
