A Fast Post-Training Pruning Framework for Transformers
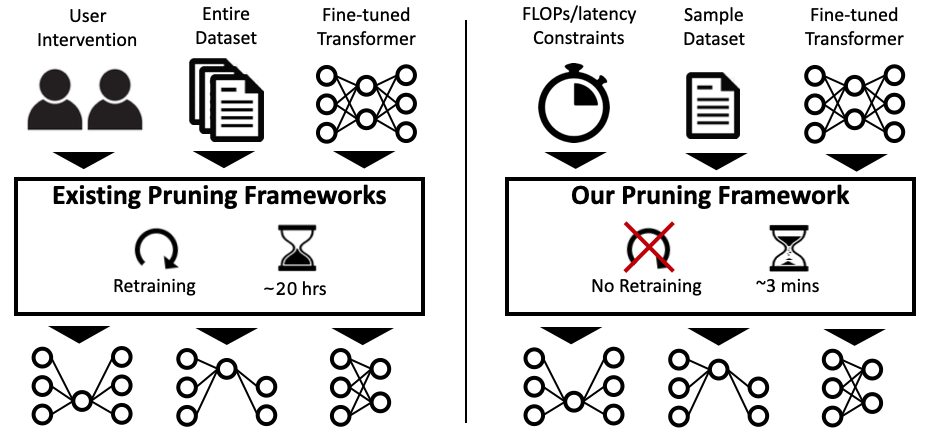
Pruning is an effective way to reduce the huge inference cost of Transformer models. However, prior work on pruning Transformers requires retraining the models. This can add high training cost and high complexity to model deployment, making it difficult to use in many practical situations. To address this, we propose a fast post-training pruning framework for Transformers that does not require any retraining. Given a resource constraint and a sample dataset, our framework automatically prunes the Transformer model using structured sparsity methods. To retain high accuracy without retraining, we introduce three novel techniques: (i) a lightweight mask search algorithm that finds which heads and filters to prune based on the Fisher information; (ii) mask rearrangement that complements the search algorithm; and (iii) mask tuning that reconstructs the output activations for each layer. We apply our method to BERT-base and DistilBERT, and we evaluate its effectiveness on GLUE and SQuAD benchmarks. Our framework achieves up to 2.0x reduction in FLOPs and 1.56x speedup in inference latency, while maintaining < 1% loss in accuracy. Importantly, our framework prunes Transformers in less than 3 minutes on a single GPU, which is over two orders of magnitude faster than existing pruning approaches that retrain the models.
PDF Abstract
 GLUE
GLUE
 SST
SST
 SQuAD
SQuAD
 MultiNLI
MultiNLI
 QNLI
QNLI
 MRPC
MRPC
