A Multifaceted Benchmarking of Synthetic Electronic Health Record Generation Models
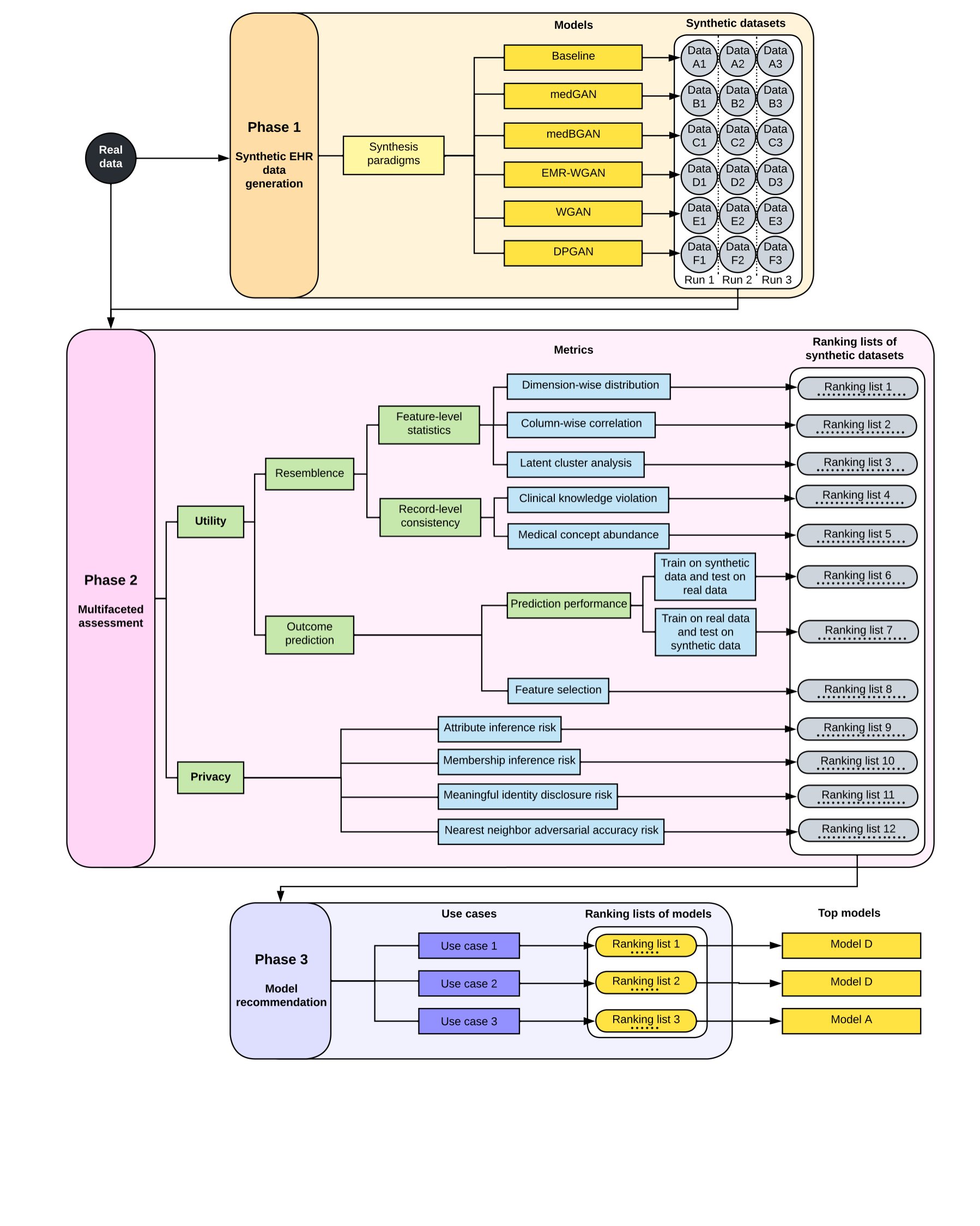
Synthetic health data have the potential to mitigate privacy concerns when sharing data to support biomedical research and the development of innovative healthcare applications. Modern approaches for data generation based on machine learning, generative adversarial networks (GAN) methods in particular, continue to evolve and demonstrate remarkable potential. Yet there is a lack of a systematic assessment framework to benchmark methods as they emerge and determine which methods are most appropriate for which use cases. In this work, we introduce a generalizable benchmarking framework to appraise key characteristics of synthetic health data with respect to utility and privacy metrics. We apply the framework to evaluate synthetic data generation methods for electronic health records (EHRs) data from two large academic medical centers with respect to several use cases. The results illustrate that there is a utility-privacy tradeoff for sharing synthetic EHR data. The results further indicate that no method is unequivocally the best on all criteria in each use case, which makes it evident why synthetic data generation methods need to be assessed in context.
PDF Abstract

