A New Look at an Old Problem: A Universal Learning Approach to Linear Regression
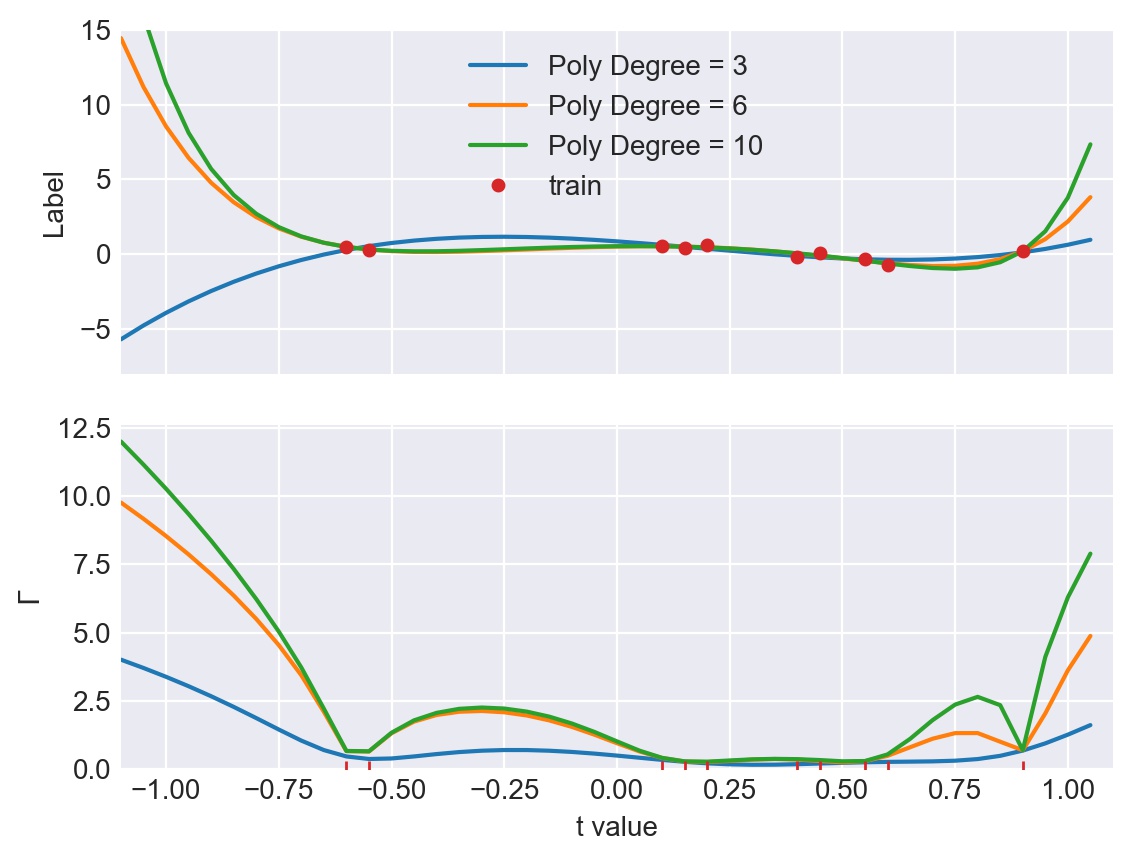
Linear regression is a classical paradigm in statistics. A new look at it is provided via the lens of universal learning. In applying universal learning to linear regression the hypotheses class represents the label $y\in {\cal R}$ as a linear combination of the feature vector $x^T\theta$ where $x\in {\cal R}^M$, within a Gaussian error. The Predictive Normalized Maximum Likelihood (pNML) solution for universal learning of individual data can be expressed analytically in this case, as well as its associated learnability measure. Interestingly, the situation where the number of parameters $M$ may even be larger than the number of training samples $N$ can be examined. As expected, in this case learnability cannot be attained in every situation; nevertheless, if the test vector resides mostly in a subspace spanned by the eigenvectors associated with the large eigenvalues of the empirical correlation matrix of the training data, linear regression can generalize despite the fact that it uses an ``over-parametrized'' model. We demonstrate the results with a simulation of fitting a polynomial to data with a possibly large polynomial degree.
PDF Abstract

