A Simple Fusion of Deep and Shallow Learning for Acoustic Scene Classification
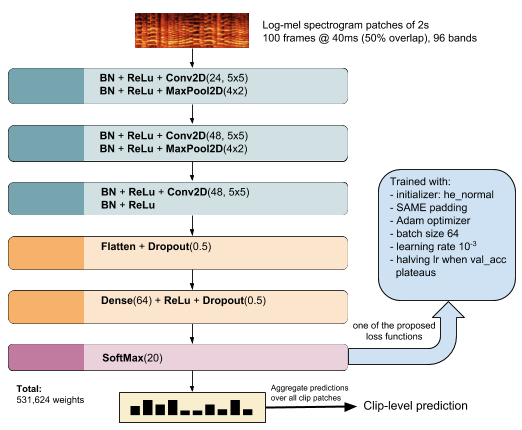
In the past, Acoustic Scene Classification systems have been based on hand crafting audio features that are input to a classifier. Nowadays, the common trend is to adopt data driven techniques, e.g., deep learning, where audio representations are learned from data. In this paper, we propose a system that consists of a simple fusion of two methods of the aforementioned types: a deep learning approach where log-scaled mel-spectrograms are input to a convolutional neural network, and a feature engineering approach, where a collection of hand-crafted features is input to a gradient boosting machine. We first show that both methods provide complementary information to some extent. Then, we use a simple late fusion strategy to combine both methods. We report classification accuracy of each method individually and the combined system on the TUT Acoustic Scenes 2017 dataset. The proposed fused system outperforms each of the individual methods and attains a classification accuracy of 72.8% on the evaluation set, improving the baseline system by 11.8%.
PDF Abstract




