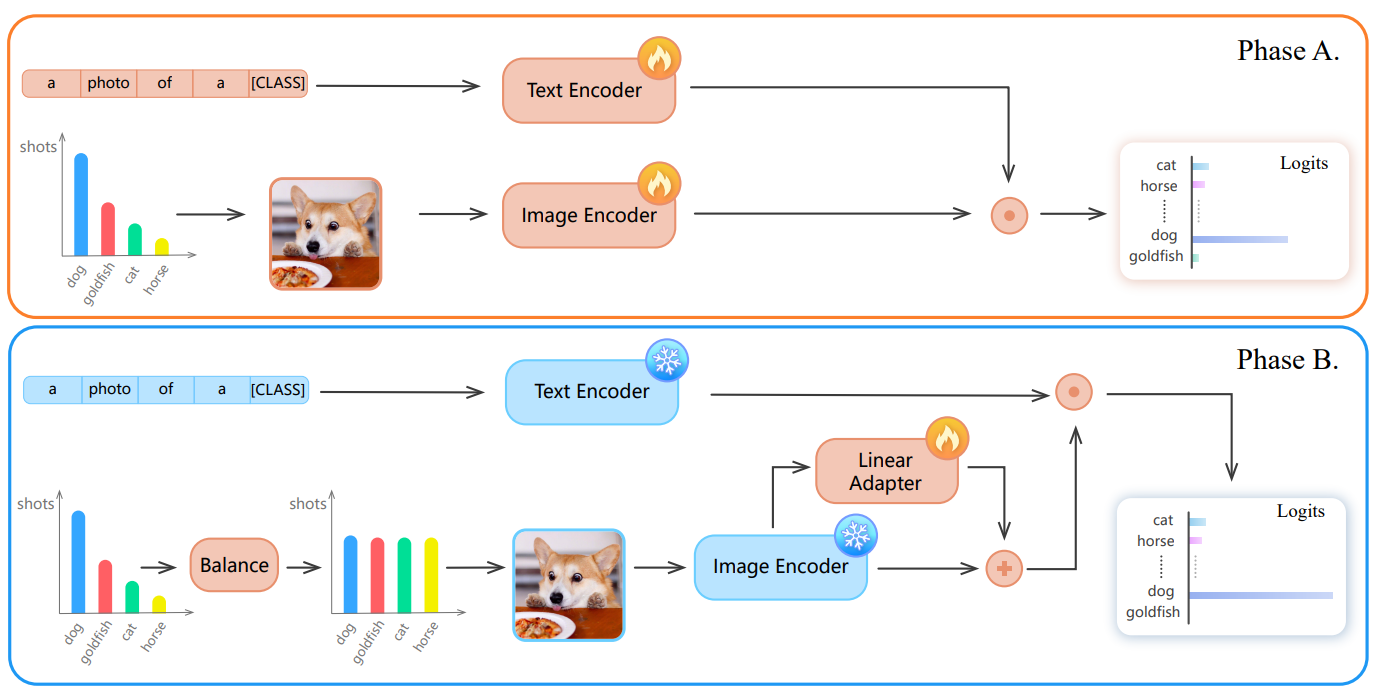
A Simple Long-Tailed Recognition Baseline via Vision-Language Model
The visual world naturally exhibits a long-tailed distribution of open classes, which poses great challenges to modern visual systems. Existing approaches either perform class re-balancing strategies or directly improve network modules to address the problem. However, they still train models with a finite set of predefined labels, limiting their supervision information and restricting their transferability to novel instances. Recent advances in large-scale contrastive visual-language pretraining shed light on a new pathway for visual recognition. With open-vocabulary supervisions, pretrained contrastive vision-language models learn powerful multimodal representations that are promising to handle data deficiency and unseen concepts. By calculating the semantic similarity between visual and text inputs, visual recognition is converted to a vision-language matching problem. Inspired by this, we propose BALLAD to leverage contrastive vision-language models for long-tailed recognition. We first continue pretraining the vision-language backbone through contrastive learning on a specific long-tailed target dataset. Afterward, we freeze the backbone and further employ an additional adapter layer to enhance the representations of tail classes on balanced training samples built with re-sampling strategies. Extensive experiments have been conducted on three popular long-tailed recognition benchmarks. As a result, our simple and effective approach sets the new state-of-the-art performances and outperforms competitive baselines with a large margin. Code is released at https://github.com/gaopengcuhk/BALLAD.
PDF AbstractCode





Datasets
 ImageNet
ImageNet
 CIFAR-100
CIFAR-100
 Places
Places
Results from the Paper
 Ranked #4 on
Long-tail Learning
on Places-LT
(using extra training data)
Ranked #4 on
Long-tail Learning
on Places-LT
(using extra training data)
