A Survey of Pretraining on Graphs: Taxonomy, Methods, and Applications
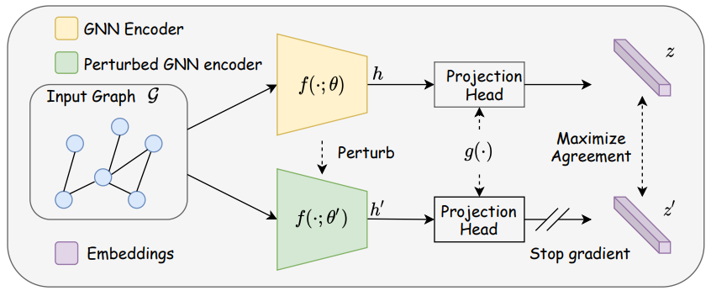
Pretrained Language Models (PLMs) such as BERT have revolutionized the landscape of Natural Language Processing (NLP). Inspired by their proliferation, tremendous efforts have been devoted to Pretrained Graph Models (PGMs). Owing to the powerful model architectures of PGMs, abundant knowledge from massive labeled and unlabeled graph data can be captured. The knowledge implicitly encoded in model parameters can benefit various downstream tasks and help to alleviate several fundamental issues of learning on graphs. In this paper, we provide the first comprehensive survey for PGMs. We firstly present the limitations of graph representation learning and thus introduce the motivation for graph pre-training. Then, we systematically categorize existing PGMs based on a taxonomy from four different perspectives. Next, we present the applications of PGMs in social recommendation and drug discovery. Finally, we outline several promising research directions that can serve as a guideline for future research.
PDF Abstract




