A Systematic Comparison of Phonetic Aware Techniques for Speech Enhancement
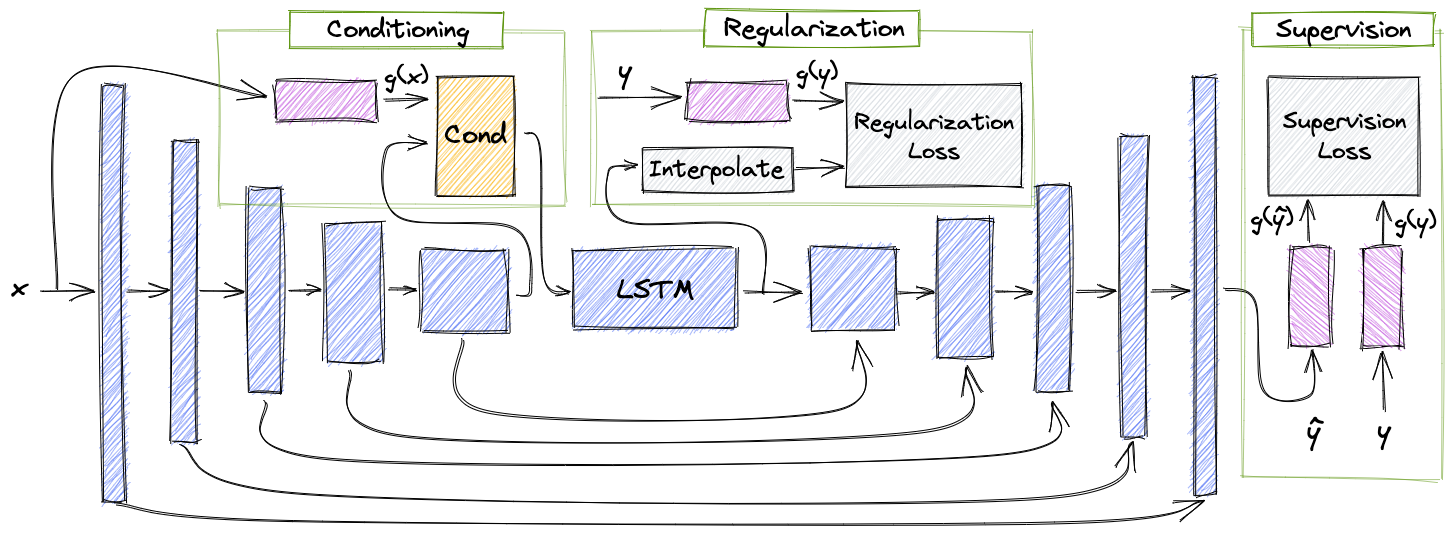
Speech enhancement has seen great improvement in recent years using end-to-end neural networks. However, most models are agnostic to the spoken phonetic content. Recently, several studies suggested phonetic-aware speech enhancement, mostly using perceptual supervision. Yet, injecting phonetic features during model optimization can take additional forms (e.g., model conditioning). In this paper, we conduct a systematic comparison between different methods of incorporating phonetic information in a speech enhancement model. By conducting a series of controlled experiments, we observe the influence of different phonetic content models as well as various feature-injection techniques on enhancement performance, considering both causal and non-causal models. Specifically, we evaluate three settings for injecting phonetic information, namely: i) feature conditioning; ii) perceptual supervision; and iii) regularization. Phonetic features are obtained using an intermediate layer of either a supervised pre-trained Automatic Speech Recognition (ASR) model or by using a pre-trained Self-Supervised Learning (SSL) model. We further observe the effect of choosing different embedding layers on performance, considering both manual and learned configurations. Results suggest that using a SSL model as phonetic features outperforms the ASR one in most cases. Interestingly, the conditioning setting performs best among the evaluated configurations.
PDF Abstract




