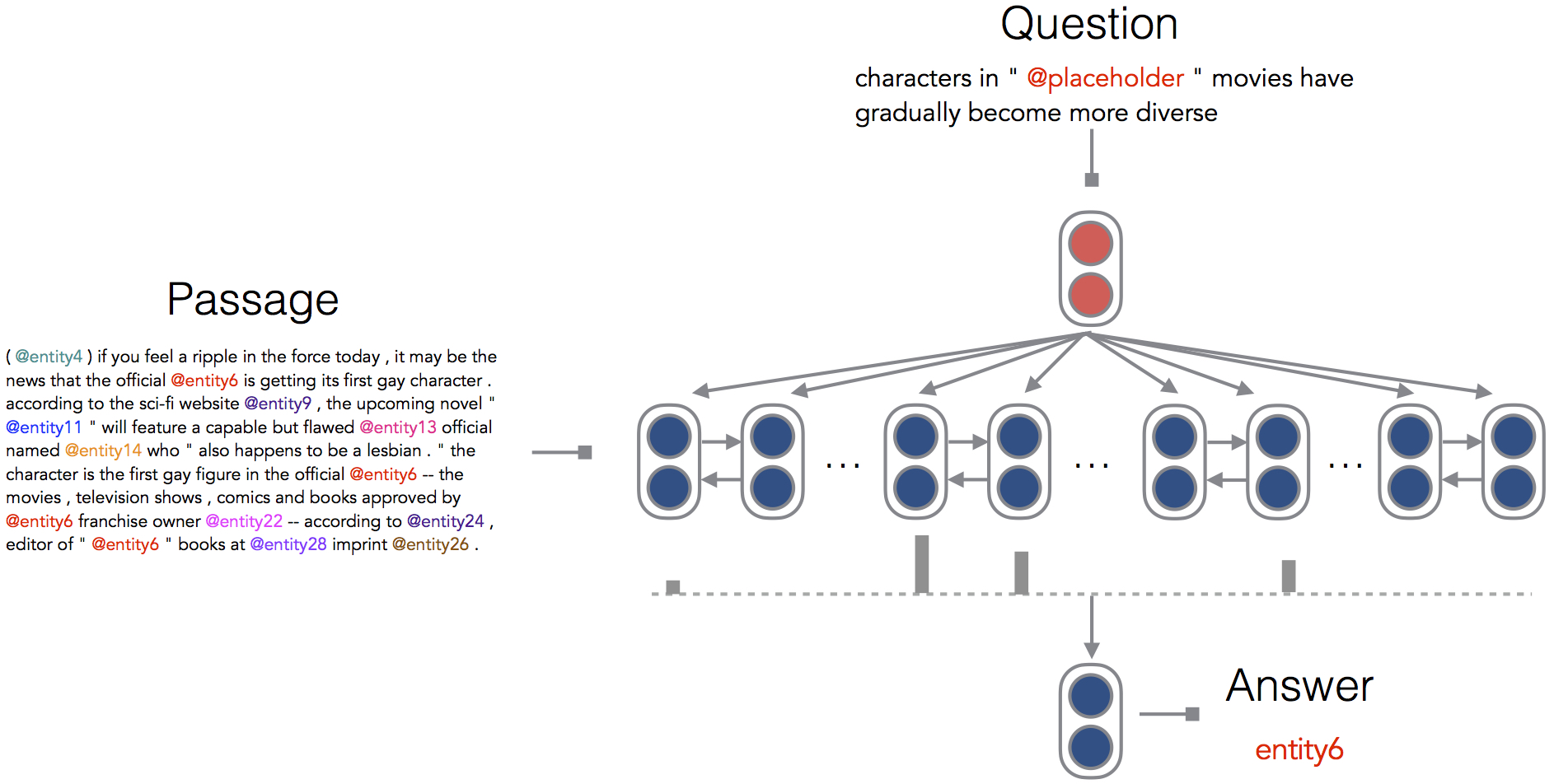
A Thorough Examination of the CNN/Daily Mail Reading Comprehension Task
Enabling a computer to understand a document so that it can answer comprehension questions is a central, yet unsolved goal of NLP. A key factor impeding its solution by machine learned systems is the limited availability of human-annotated data. Hermann et al. (2015) seek to solve this problem by creating over a million training examples by pairing CNN and Daily Mail news articles with their summarized bullet points, and show that a neural network can then be trained to give good performance on this task. In this paper, we conduct a thorough examination of this new reading comprehension task. Our primary aim is to understand what depth of language understanding is required to do well on this task. We approach this from one side by doing a careful hand-analysis of a small subset of the problems and from the other by showing that simple, carefully designed systems can obtain accuracies of 73.6% and 76.6% on these two datasets, exceeding current state-of-the-art results by 7-10% and approaching what we believe is the ceiling for performance on this task.
PDF Abstract ACL 2016 PDF ACL 2016 Abstract

 CNN/Daily Mail
CNN/Daily Mail
 MCTest
MCTest

