A Token-level Reference-free Hallucination Detection Benchmark for Free-form Text Generation
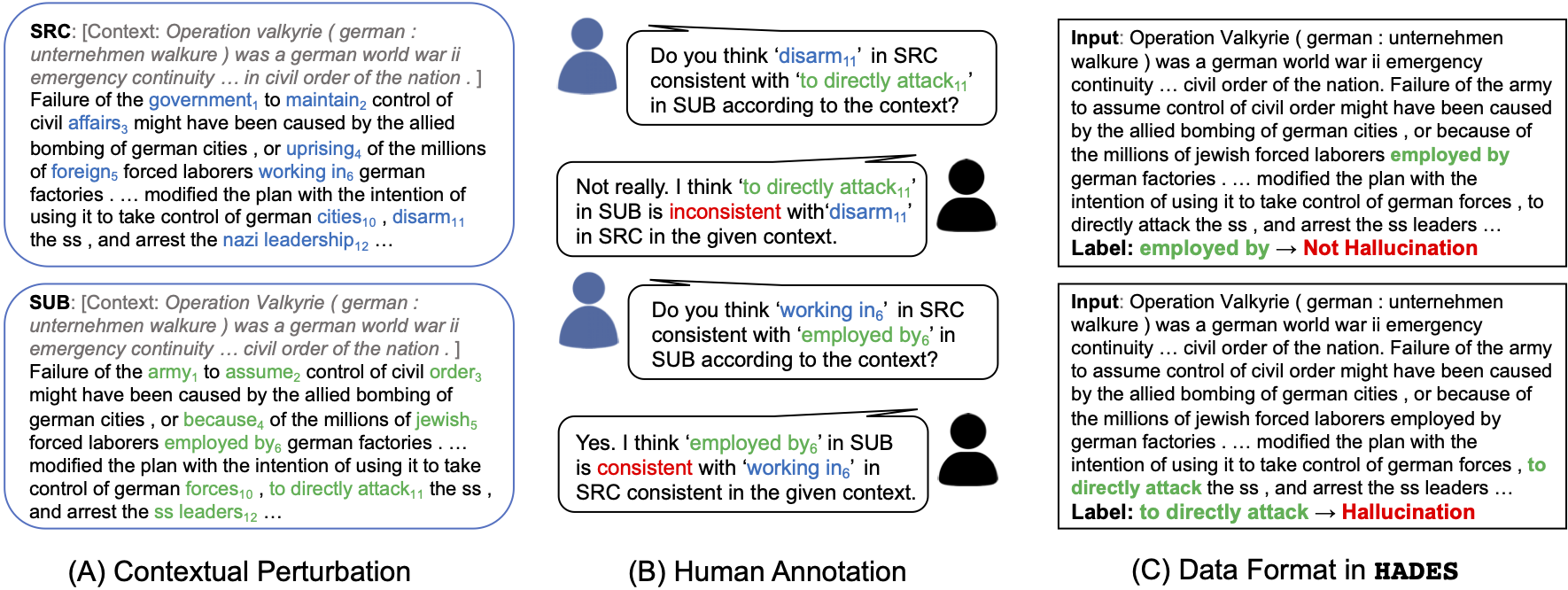
Large pretrained generative models like GPT-3 often suffer from hallucinating non-existent or incorrect content, which undermines their potential merits in real applications. Existing work usually attempts to detect these hallucinations based on a corresponding oracle reference at a sentence or document level. However ground-truth references may not be readily available for many free-form text generation applications, and sentence- or document-level detection may fail to provide the fine-grained signals that would prevent fallacious content in real time. As a first step to addressing these issues, we propose a novel token-level, reference-free hallucination detection task and an associated annotated dataset named HaDes (HAllucination DEtection dataSet). To create this dataset, we first perturb a large number of text segments extracted from English language Wikipedia, and then verify these with crowd-sourced annotations. To mitigate label imbalance during annotation, we utilize an iterative model-in-loop strategy. We conduct comprehensive data analyses and create multiple baseline models.
PDF Abstract ACL 2022 PDF ACL 2022 AbstractCode



Datasets
Introduced in the Paper:
HaDes