A unified framework for Hamiltonian deep neural networks
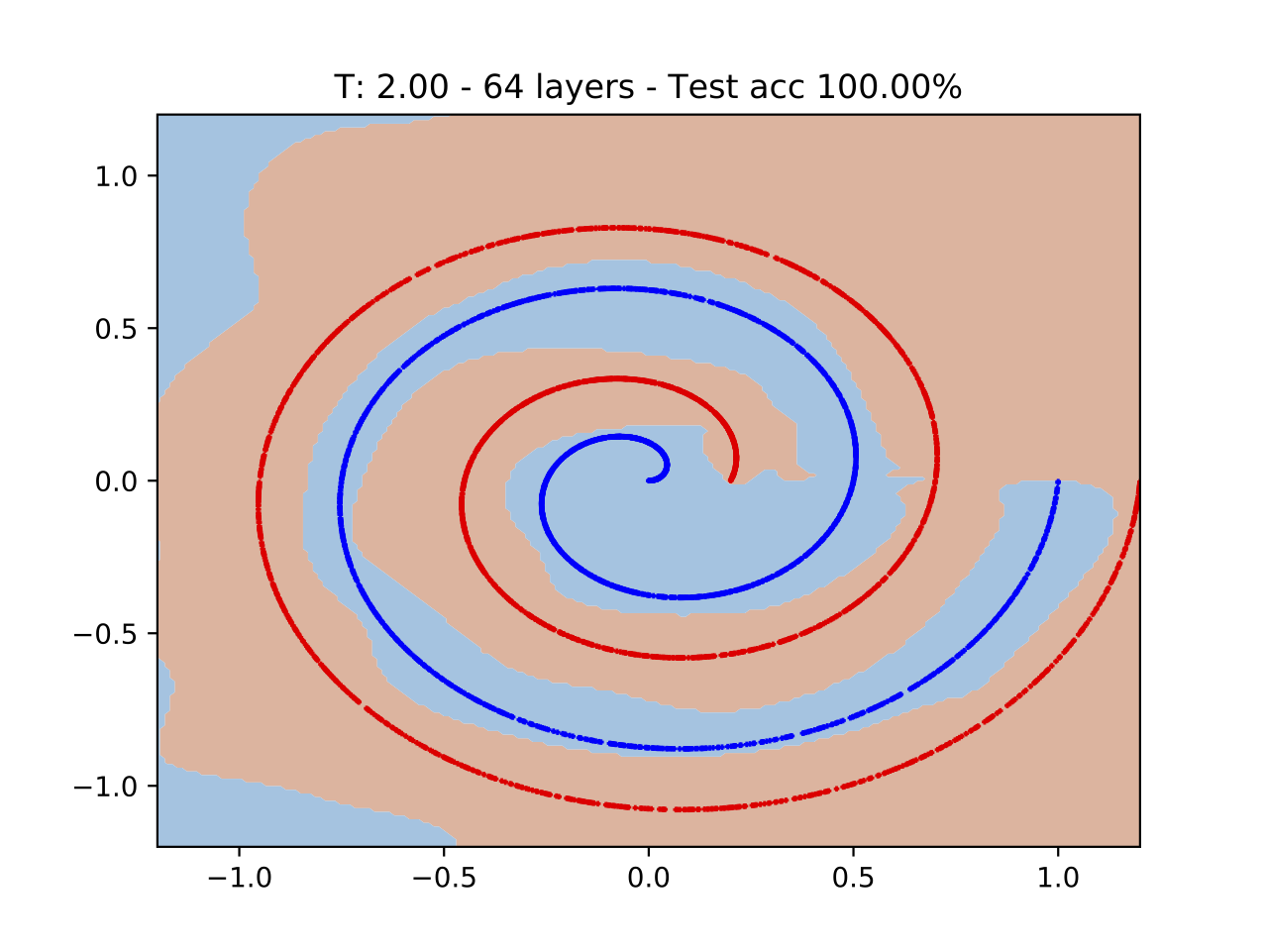
Training deep neural networks (DNNs) can be difficult due to the occurrence of vanishing/exploding gradients during weight optimization. To avoid this problem, we propose a class of DNNs stemming from the time discretization of Hamiltonian systems. The time-invariant version of the corresponding Hamiltonian models enjoys marginal stability, a property that, as shown in previous works and for specific DNNs architectures, can mitigate convergence to zero or divergence of gradients. In the present paper, we formally study this feature by deriving and analysing the backward gradient dynamics in continuous time. The proposed Hamiltonian framework, besides encompassing existing networks inspired by marginally stable ODEs, allows one to derive new and more expressive architectures. The good performance of the novel DNNs is demonstrated on benchmark classification problems, including digit recognition using the MNIST dataset.
PDF Abstract
