Diffiner: A Versatile Diffusion-based Generative Refiner for Speech Enhancement
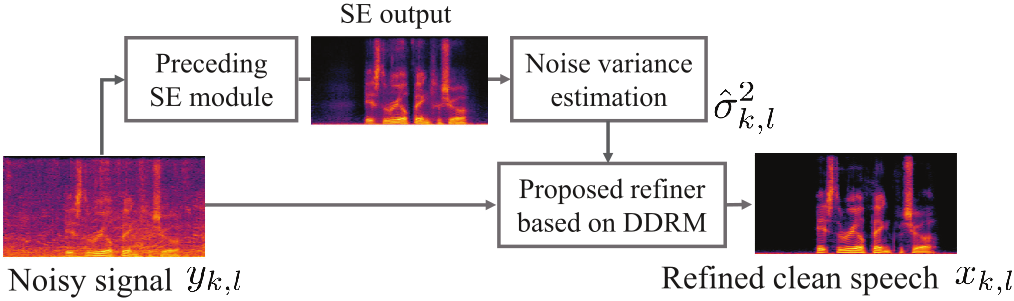
Although deep neural network (DNN)-based speech enhancement (SE) methods outperform the previous non-DNN-based ones, they often degrade the perceptual quality of generated outputs. To tackle this problem, we introduce a DNN-based generative refiner, Diffiner, aiming to improve perceptual speech quality pre-processed by an SE method. We train a diffusion-based generative model by utilizing a dataset consisting of clean speech only. Then, our refiner effectively mixes clean parts newly generated via denoising diffusion restoration into the degraded and distorted parts caused by a preceding SE method, resulting in refined speech. Once our refiner is trained on a set of clean speech, it can be applied to various SE methods without additional training specialized for each SE module. Therefore, our refiner can be a versatile post-processing module w.r.t. SE methods and has high potential in terms of modularity. Experimental results show that our method improved perceptual speech quality regardless of the preceding SE methods used.
PDF Abstract


