Accumulated Gradient Normalization
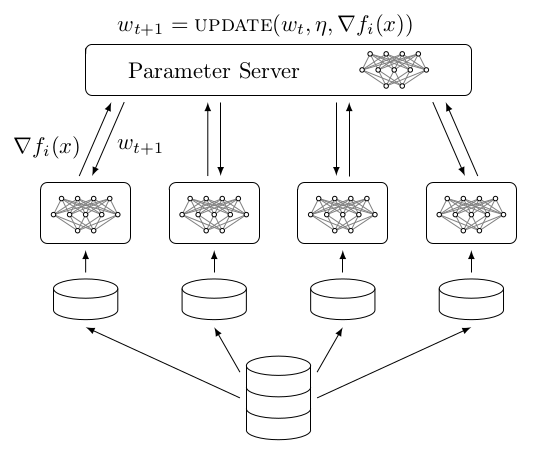
This work addresses the instability in asynchronous data parallel optimization. It does so by introducing a novel distributed optimizer which is able to efficiently optimize a centralized model under communication constraints. The optimizer achieves this by pushing a normalized sequence of first-order gradients to a parameter server. This implies that the magnitude of a worker delta is smaller compared to an accumulated gradient, and provides a better direction towards a minimum compared to first-order gradients, which in turn also forces possible implicit momentum fluctuations to be more aligned since we make the assumption that all workers contribute towards a single minima. As a result, our approach mitigates the parameter staleness problem more effectively since staleness in asynchrony induces (implicit) momentum, and achieves a better convergence rate compared to other optimizers such as asynchronous EASGD and DynSGD, which we show empirically.
PDF Abstract
