ActionCLIP: A New Paradigm for Video Action Recognition
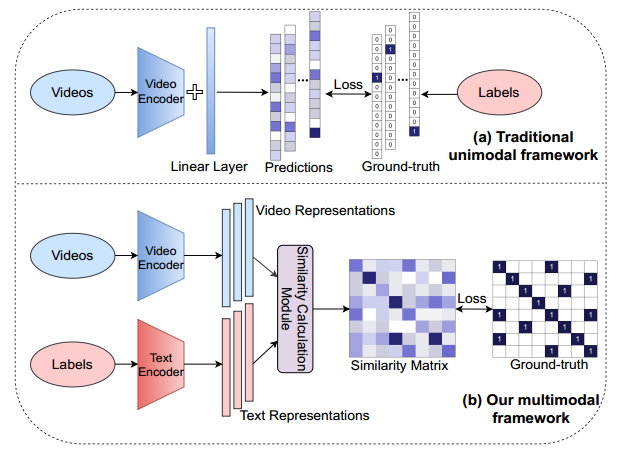
The canonical approach to video action recognition dictates a neural model to do a classic and standard 1-of-N majority vote task. They are trained to predict a fixed set of predefined categories, limiting their transferable ability on new datasets with unseen concepts. In this paper, we provide a new perspective on action recognition by attaching importance to the semantic information of label texts rather than simply mapping them into numbers. Specifically, we model this task as a video-text matching problem within a multimodal learning framework, which strengthens the video representation with more semantic language supervision and enables our model to do zero-shot action recognition without any further labeled data or parameters requirements. Moreover, to handle the deficiency of label texts and make use of tremendous web data, we propose a new paradigm based on this multimodal learning framework for action recognition, which we dub "pre-train, prompt and fine-tune". This paradigm first learns powerful representations from pre-training on a large amount of web image-text or video-text data. Then it makes the action recognition task to act more like pre-training problems via prompt engineering. Finally, it end-to-end fine-tunes on target datasets to obtain strong performance. We give an instantiation of the new paradigm, ActionCLIP, which not only has superior and flexible zero-shot/few-shot transfer ability but also reaches a top performance on general action recognition task, achieving 83.8% top-1 accuracy on Kinetics-400 with a ViT-B/16 as the backbone. Code is available at https://github.com/sallymmx/ActionCLIP.git
PDF Abstract





 UCF101
UCF101
 Kinetics
Kinetics
 HMDB51
HMDB51
 Kinetics 400
Kinetics 400
 Charades
Charades

