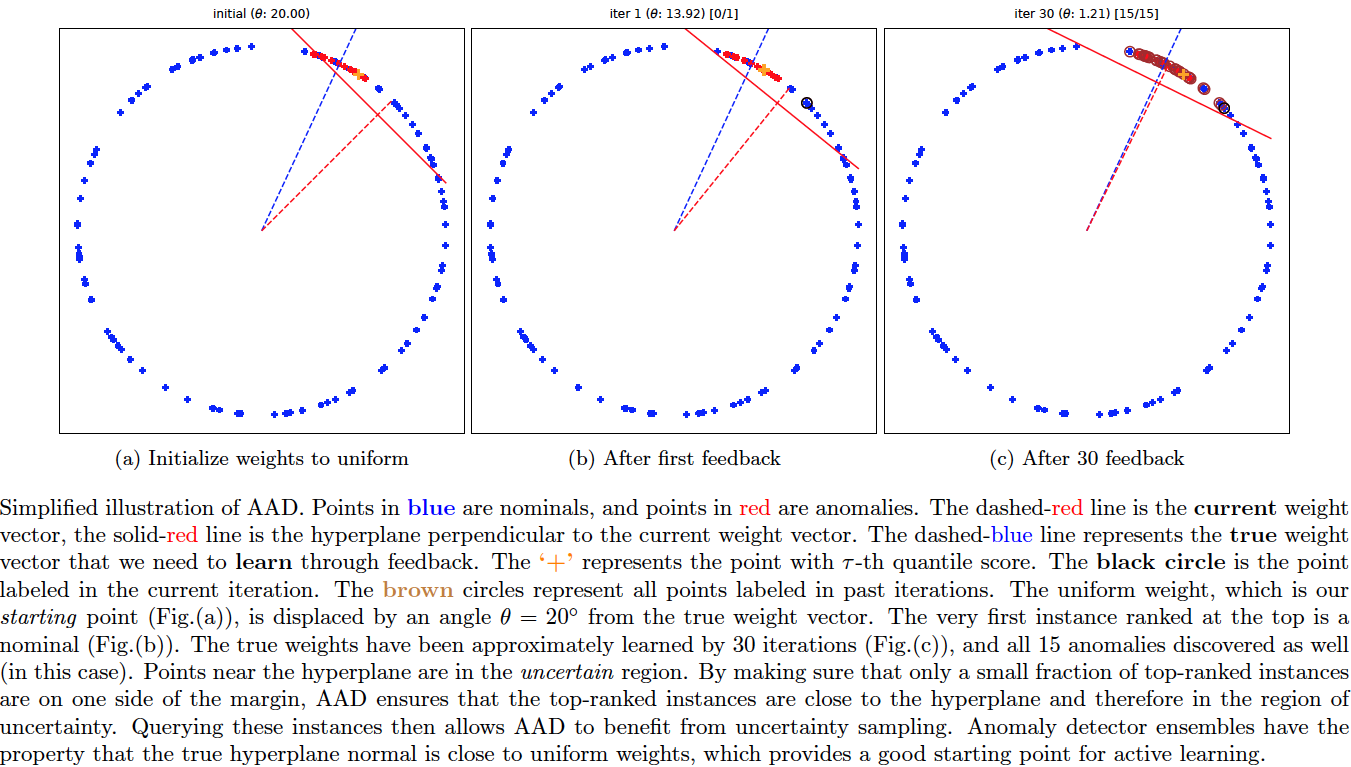
Active Anomaly Detection via Ensembles
In critical applications of anomaly detection including computer security and fraud prevention, the anomaly detector must be configurable by the analyst to minimize the effort on false positives. One important way to configure the anomaly detector is by providing true labels for a few instances. We study the problem of label-efficient active learning to automatically tune anomaly detection ensembles and make four main contributions. First, we present an important insight into how anomaly detector ensembles are naturally suited for active learning. This insight allows us to relate the greedy querying strategy to uncertainty sampling, with implications for label-efficiency. Second, we present a novel formalism called compact description to describe the discovered anomalies and show that it can also be employed to improve the diversity of the instances presented to the analyst without loss in the anomaly discovery rate. Third, we present a novel data drift detection algorithm that not only detects the drift robustly, but also allows us to take corrective actions to adapt the detector in a principled manner. Fourth, we present extensive experiments to evaluate our insights and algorithms in both batch and streaming settings. Our results show that in addition to discovering significantly more anomalies than state-of-the-art unsupervised baselines, our active learning algorithms under the streaming-data setup are competitive with the batch setup.
PDF Abstract


