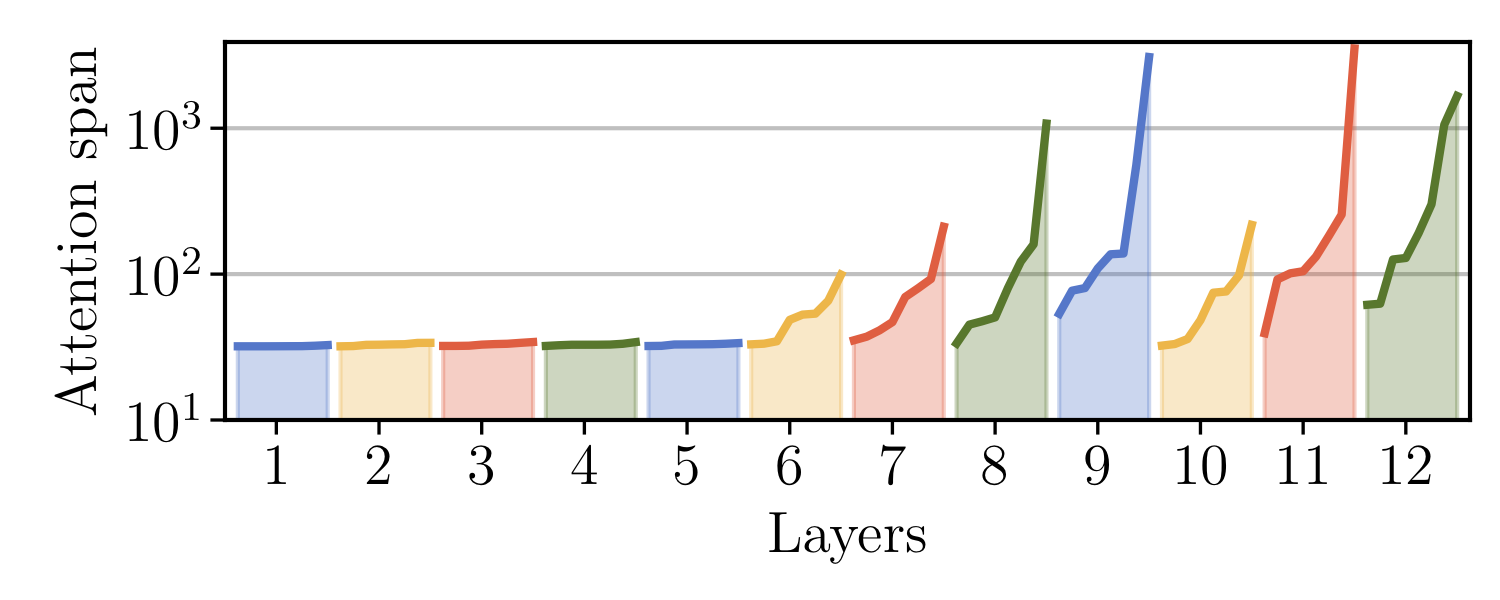
Adaptive Attention Span in Transformers
We propose a novel self-attention mechanism that can learn its optimal attention span. This allows us to extend significantly the maximum context size used in Transformer, while maintaining control over their memory footprint and computational time. We show the effectiveness of our approach on the task of character level language modeling, where we achieve state-of-the-art performances on text8 and enwiki8 by using a maximum context of 8k characters.
PDF Abstract ACL 2019 PDF ACL 2019 AbstractCode


Tasks


Datasets

Methods
Absolute Position Encodings •
Adam •
Adaptive Masking •
Adaptive Span Transformer •
Attention Dropout •
BPE •
Dense Connections •
Dropout •
Embedding Dropout •
L1 Regularization •
Label Smoothing •
Layer Normalization •
Linear Layer •
Multi-Head Attention •
Position-Wise Feed-Forward Layer •
ReLU •
Residual Connection •
Scaled Dot-Product Attention •
Softmax •
Transformer
