Adaptive Gradient Methods Converge Faster with Over-Parameterization (but you should do a line-search)
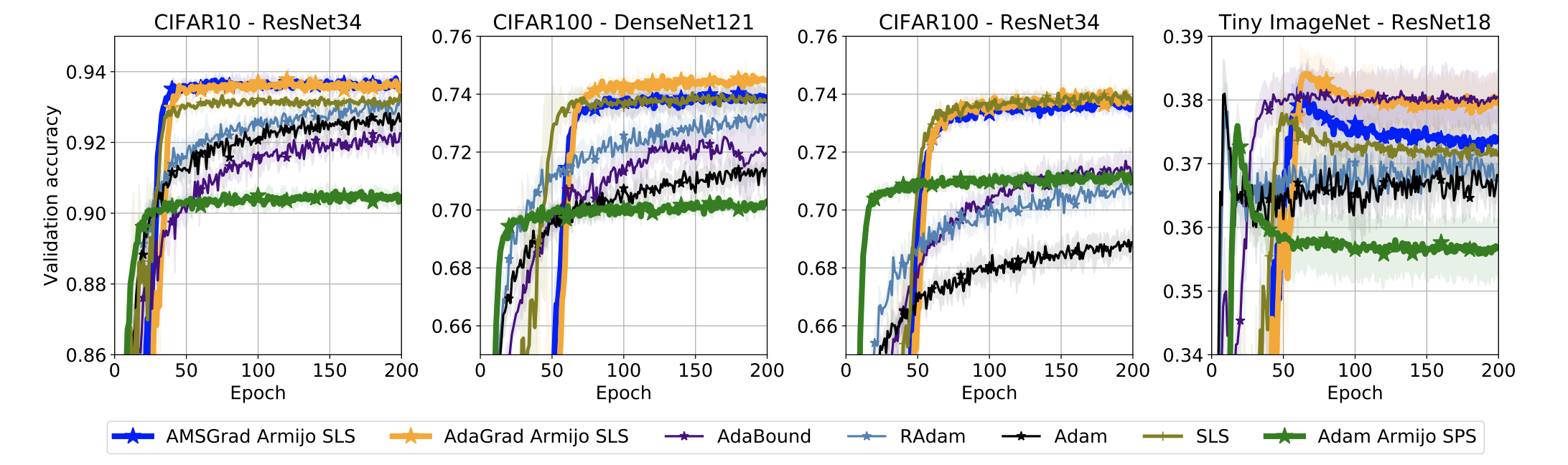
Adaptive gradient methods are typically used for training over-parameterized models. To better understand their behaviour, we study a simplistic setting -- smooth, convex losses with models over-parameterized enough to interpolate the data. In this setting, we prove that AMSGrad with constant step-size and momentum converges to the minimizer at a faster $O(1/T)$ rate. When interpolation is only approximately satisfied, constant step-size AMSGrad converges to a neighbourhood of the solution at the same rate, while AdaGrad is robust to the violation of interpolation. However, even for simple convex problems satisfying interpolation, the empirical performance of both methods heavily depends on the step-size and requires tuning, questioning their adaptivity. We alleviate this problem by automatically determining the step-size using stochastic line-search or Polyak step-sizes. With these techniques, we prove that both AdaGrad and AMSGrad retain their convergence guarantees, without needing to know problem-dependent constants. Empirically, we demonstrate that these techniques improve the convergence and generalization of adaptive gradient methods across tasks, from binary classification with kernel mappings to multi-class classification with deep networks.
PDF Abstract

