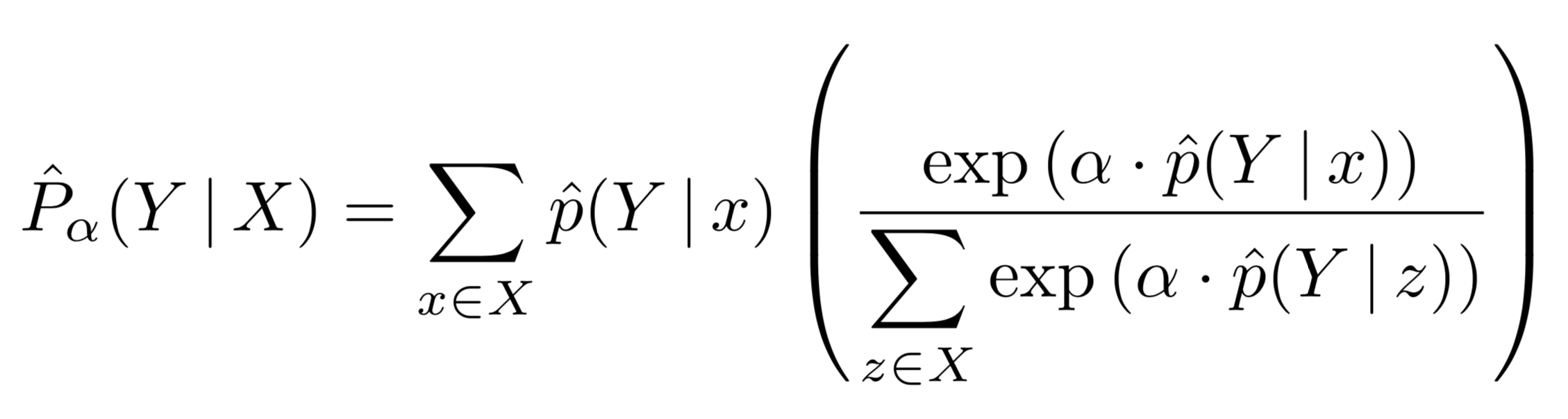
Adaptive pooling operators for weakly labeled sound event detection
Sound event detection (SED) methods are tasked with labeling segments of audio recordings by the presence of active sound sources. SED is typically posed as a supervised machine learning problem, requiring strong annotations for the presence or absence of each sound source at every time instant within the recording. However, strong annotations of this type are both labor- and cost-intensive for human annotators to produce, which limits the practical scalability of SED methods. In this work, we treat SED as a multiple instance learning (MIL) problem, where training labels are static over a short excerpt, indicating the presence or absence of sound sources but not their temporal locality. The models, however, must still produce temporally dynamic predictions, which must be aggregated (pooled) when comparing against static labels during training. To facilitate this aggregation, we develop a family of adaptive pooling operators---referred to as auto-pool---which smoothly interpolate between common pooling operators, such as min-, max-, or average-pooling, and automatically adapt to the characteristics of the sound sources in question. We evaluate the proposed pooling operators on three datasets, and demonstrate that in each case, the proposed methods outperform non-adaptive pooling operators for static prediction, and nearly match the performance of models trained with strong, dynamic annotations. The proposed method is evaluated in conjunction with convolutional neural networks, but can be readily applied to any differentiable model for time-series label prediction.
PDF Abstract


 AudioSet
AudioSet
