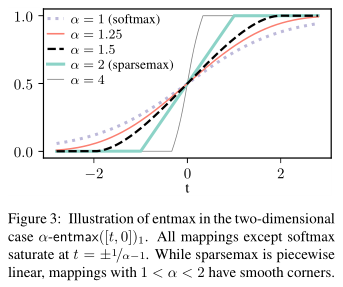
Adaptively Sparse Transformers
Attention mechanisms have become ubiquitous in NLP. Recent architectures, notably the Transformer, learn powerful context-aware word representations through layered, multi-headed attention. The multiple heads learn diverse types of word relationships. However, with standard softmax attention, all attention heads are dense, assigning a non-zero weight to all context words. In this work, we introduce the adaptively sparse Transformer, wherein attention heads have flexible, context-dependent sparsity patterns. This sparsity is accomplished by replacing softmax with $\alpha$-entmax: a differentiable generalization of softmax that allows low-scoring words to receive precisely zero weight. Moreover, we derive a method to automatically learn the $\alpha$ parameter -- which controls the shape and sparsity of $\alpha$-entmax -- allowing attention heads to choose between focused or spread-out behavior. Our adaptively sparse Transformer improves interpretability and head diversity when compared to softmax Transformers on machine translation datasets. Findings of the quantitative and qualitative analysis of our approach include that heads in different layers learn different sparsity preferences and tend to be more diverse in their attention distributions than softmax Transformers. Furthermore, at no cost in accuracy, sparsity in attention heads helps to uncover different head specializations.
PDF Abstract IJCNLP 2019 PDF IJCNLP 2019 Abstract


 WMT 2014
WMT 2014
 WMT 2016
WMT 2016
 WMT 2016 News
WMT 2016 News
