Addressing the Memory Bottleneck in AI Model Training
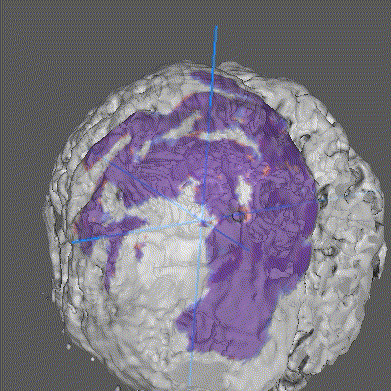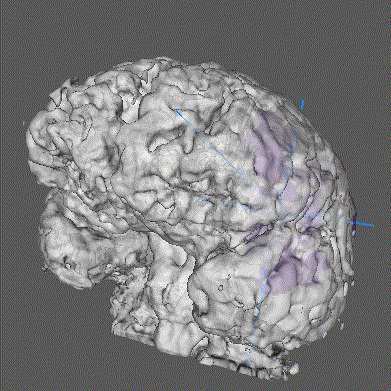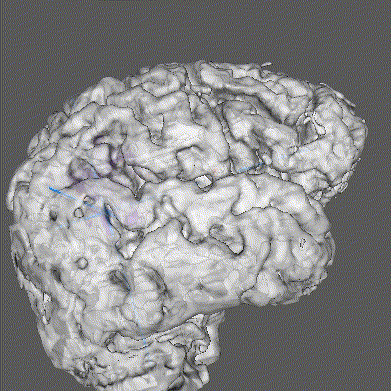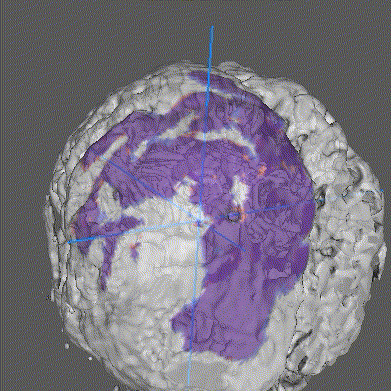
Using medical imaging as case-study, we demonstrate how Intel-optimized TensorFlow on an x86-based server equipped with 2nd Generation Intel Xeon Scalable Processors with large system memory allows for the training of memory-intensive AI/deep-learning models in a scale-up server configuration. We believe our work represents the first training of a deep neural network having large memory footprint (~ 1 TB) on a single-node server. We recommend this configuration to scientists and researchers who wish to develop large, state-of-the-art AI models but are currently limited by memory.
PDF AbstractCode

Tasks
Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
