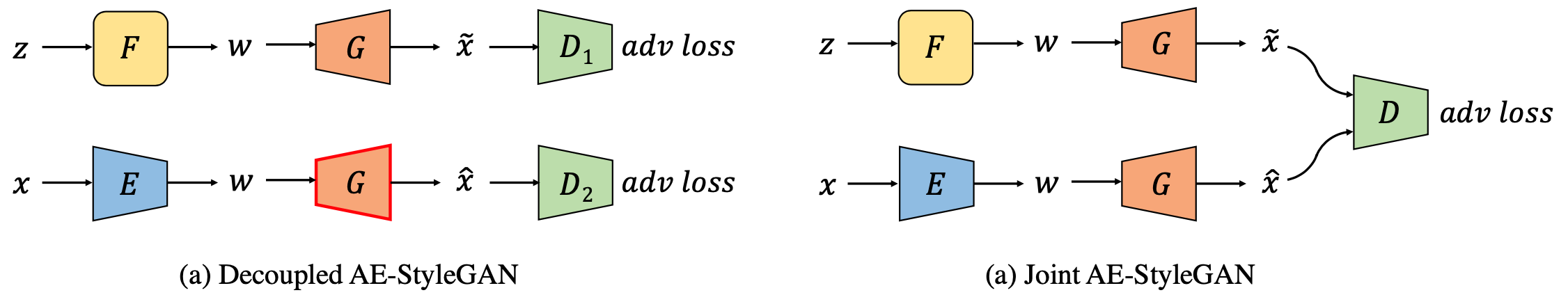
AE-StyleGAN: Improved Training of Style-Based Auto-Encoders
StyleGANs have shown impressive results on data generation and manipulation in recent years, thanks to its disentangled style latent space. A lot of efforts have been made in inverting a pretrained generator, where an encoder is trained ad hoc after the generator is trained in a two-stage fashion. In this paper, we focus on style-based generators asking a scientific question: Does forcing such a generator to reconstruct real data lead to more disentangled latent space and make the inversion process from image to latent space easy? We describe a new methodology to train a style-based autoencoder where the encoder and generator are optimized end-to-end. We show that our proposed model consistently outperforms baselines in terms of image inversion and generation quality. Supplementary, code, and pretrained models are available on the project website.
PDF Abstract
 FFHQ
FFHQ
