Align and Attend: Multimodal Summarization with Dual Contrastive Losses
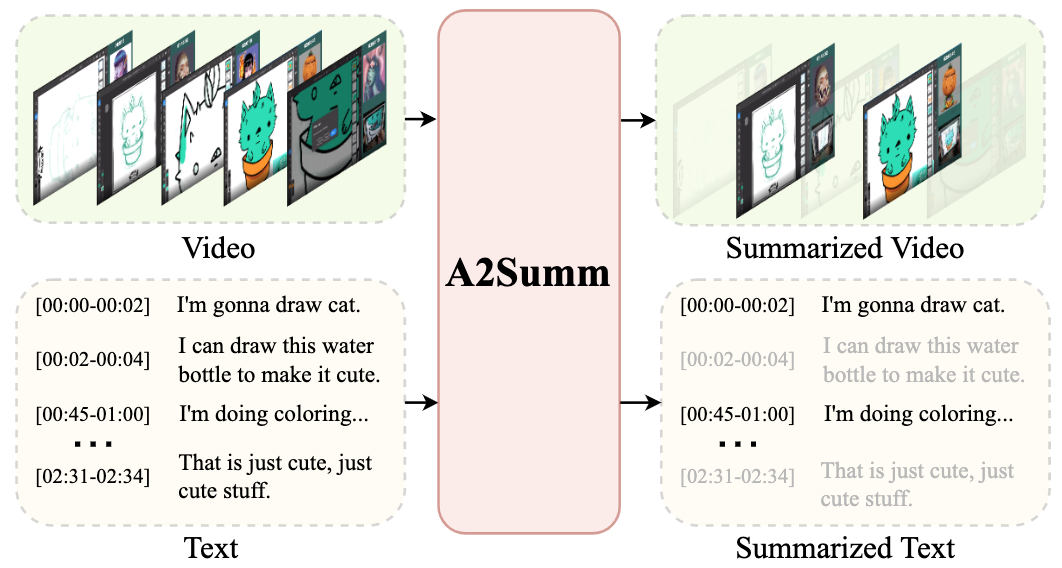
The goal of multimodal summarization is to extract the most important information from different modalities to form output summaries. Unlike the unimodal summarization, the multimodal summarization task explicitly leverages cross-modal information to help generate more reliable and high-quality summaries. However, existing methods fail to leverage the temporal correspondence between different modalities and ignore the intrinsic correlation between different samples. To address this issue, we introduce Align and Attend Multimodal Summarization (A2Summ), a unified multimodal transformer-based model which can effectively align and attend the multimodal input. In addition, we propose two novel contrastive losses to model both inter-sample and intra-sample correlations. Extensive experiments on two standard video summarization datasets (TVSum and SumMe) and two multimodal summarization datasets (Daily Mail and CNN) demonstrate the superiority of A2Summ, achieving state-of-the-art performances on all datasets. Moreover, we collected a large-scale multimodal summarization dataset BLiSS, which contains livestream videos and transcribed texts with annotated summaries. Our code and dataset are publicly available at ~\url{https://boheumd.github.io/A2Summ/}.
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract


 CNN/Daily Mail
CNN/Daily Mail
 SumMe
SumMe

