Aligning Large Language Models through Synthetic Feedback
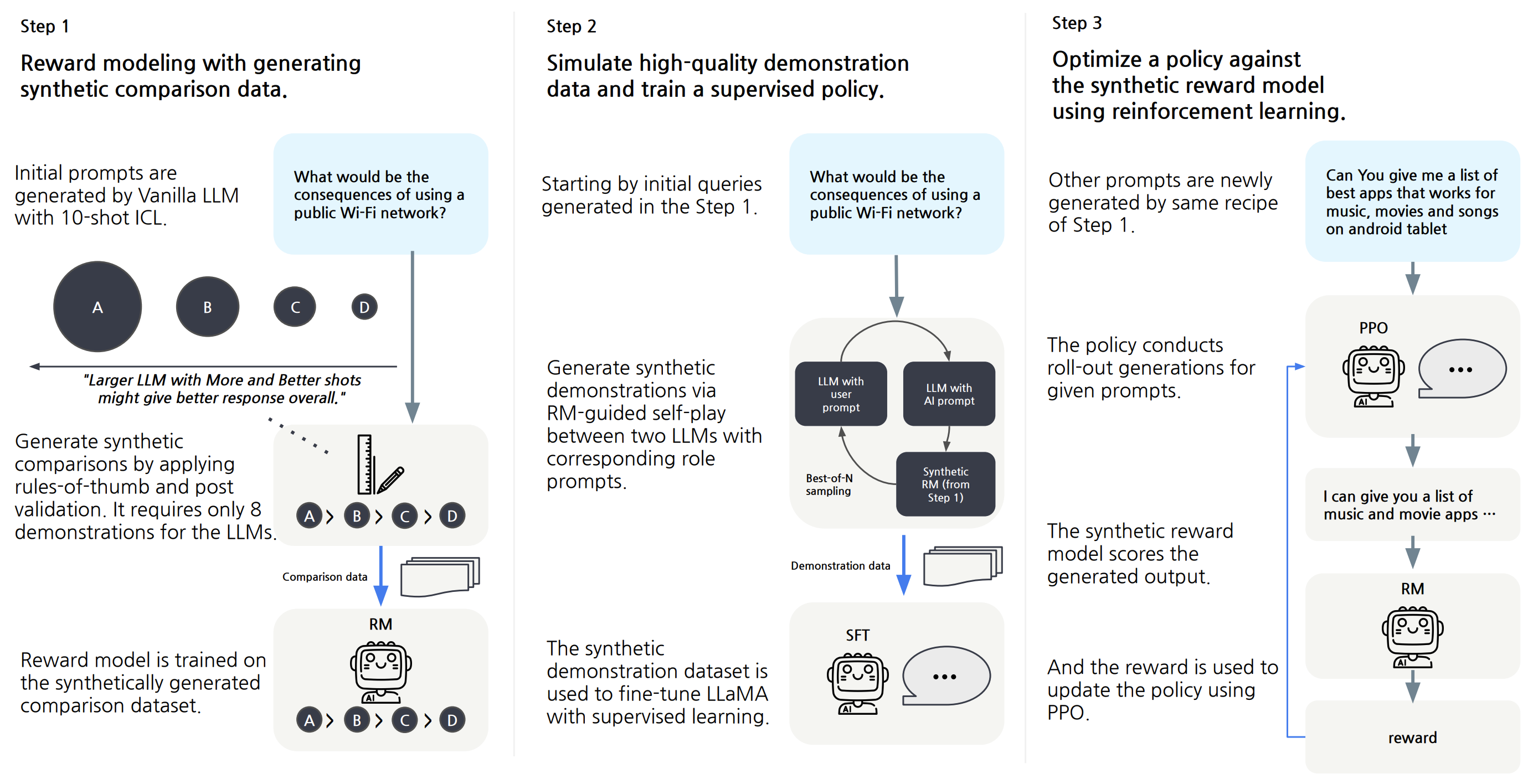
Aligning large language models (LLMs) to human values has become increasingly important as it enables sophisticated steering of LLMs. However, it requires significant human demonstrations and feedback or distillation from proprietary LLMs such as ChatGPT. In this work, we propose a novel alignment learning framework with synthetic feedback not dependent on extensive human annotations and proprietary LLMs. First, we perform reward modeling (RM) with synthetic feedback by contrasting responses from vanilla LLMs with various sizes and prompts. Then, we use the RM to simulate high-quality demonstrations to train a supervised policy and further optimize the model with reinforcement learning. Our resulting model, Aligned Language Model with Synthetic Training dataset (ALMoST), outperforms recent open-sourced models, which are trained on the outputs of InstructGPT or human-annotated demonstrations, in alignment benchmarks. In human evaluation, our model is preferred to Alpaca and Dolly-v2, 55.0% and 58.5% of the time, respectively. Further analyses demonstrate the efficacy and importance of synthetic feedback in our framework. The code is available at https://github.com/naver-ai/almost
PDF Abstract

 MMLU
MMLU
 TruthfulQA
TruthfulQA
